
ceph作为流行的SDS(Software Define Storage)开源实现备受业界关注,从本篇博文开始我们将从它提供的块服务(Rados Block Device)角度对ceph进行深入分析。
什么是Rados Block Device?
什么是ceph?
看一下官方的解释:”Ceph is a unified, distributed storage system designed for excellent performance, reliability and scalability.” 这里说的是,ceph是一个统一分布式存储系统(功能);另外,它也具有极佳的性能、可靠性和扩展性。功能和DFx兼具,很完美。
之所以说ceph是一个统一存储,是因为用户从功能上看,会认为ceph同时支持对象、块和文件三种形态(如下图所示)。其中块设备形态,就是Rados Block Device,简称RBD。
如何使用Rados Block Device?
为了使大家对ceph(RBD)有一个更直观的理解,下面我们来看看ceph(RBD)的实际使用方法:
1.创建ceph集群
ceph是一个分布式系统,内部包含许多计算、存储和网络节点,这里我们暂且把它当做一个黑盒,仅需了解使用ceph之前需要搭建这样一个集群。具体搭建方法我们会在深入分析时介绍。
2.创建pool
pool是ceph中比较重要的一个概念,一个个对象(块、文件最终也转换成对象存储)均放在pool中,管理员针对不同的pool可以采用不同的配置策略。默认情况下,一个ceph集群搭建完成后,就会有一个名为”rbd”的pool,其中专门用来存放RDB对象。我们可以用ceph集群管理命令rados在ceph客户端上查询当前已有的pools:
[root@ceph-client]# rados lspools
rbd
这里我们手动建一个新的pool,然后再查询结果:
[root@ceph-client]# rados mkpool wbpool
successfully created pool wbpool
[root@ceph-client]# rados lspools
rbd
wbpool
3.创建块设备
接下来我们使用rbd命令在wbpool池中新建一个1G大小的块设备,取名wb:
[root@ceph-client]# rbd create wb --pool wbpool --size 1G
[root@ceph-client]# rbd ls --pool wbpool
wb
4.映射块设备
创建完块设备之后,我们需要在使用RBD的主机上将它映射成一个可使用的设备:
[root@ceph-client]# rbd map wb --pool wbpool
/dev/rbd0
5.使用块设备
通过映射,我们获知RBD设备的本地访问设备为/dev/rbd0,那么我们就可以像使用本地块设备一样使用RBD块设备,例如将其格式化成文件系统并挂载使用:
[root@ceph-client]# mkfs.ext4 /dev/rbd0
[root@ceph-client]# mount /dev/rbd0 /mnt
为什么需要Rados Block Device?
ceph兼具对象、块、文件三种存储形态,支持PB级超大存储容量,同时具备较好的性能、可靠性和扩展性,因此非常适合企业级应用存储需求,公有云、私有云都有ceph成功部署的案例。Redhat将其收购后,更是进一步加速了它的应用和推广。
三种存储形态中,对象和块相对更稳定一些;块设备方式可以完全兼容已有应用,因此使用范围更为广泛。
如何实现Rados Block Device?
物理视角-ceph集群结构
我们已经知道ceph是一个集群系统,那么从物理视角深入看,集群内部有哪些部件?他们又是如何相互协作对外提供服务的?
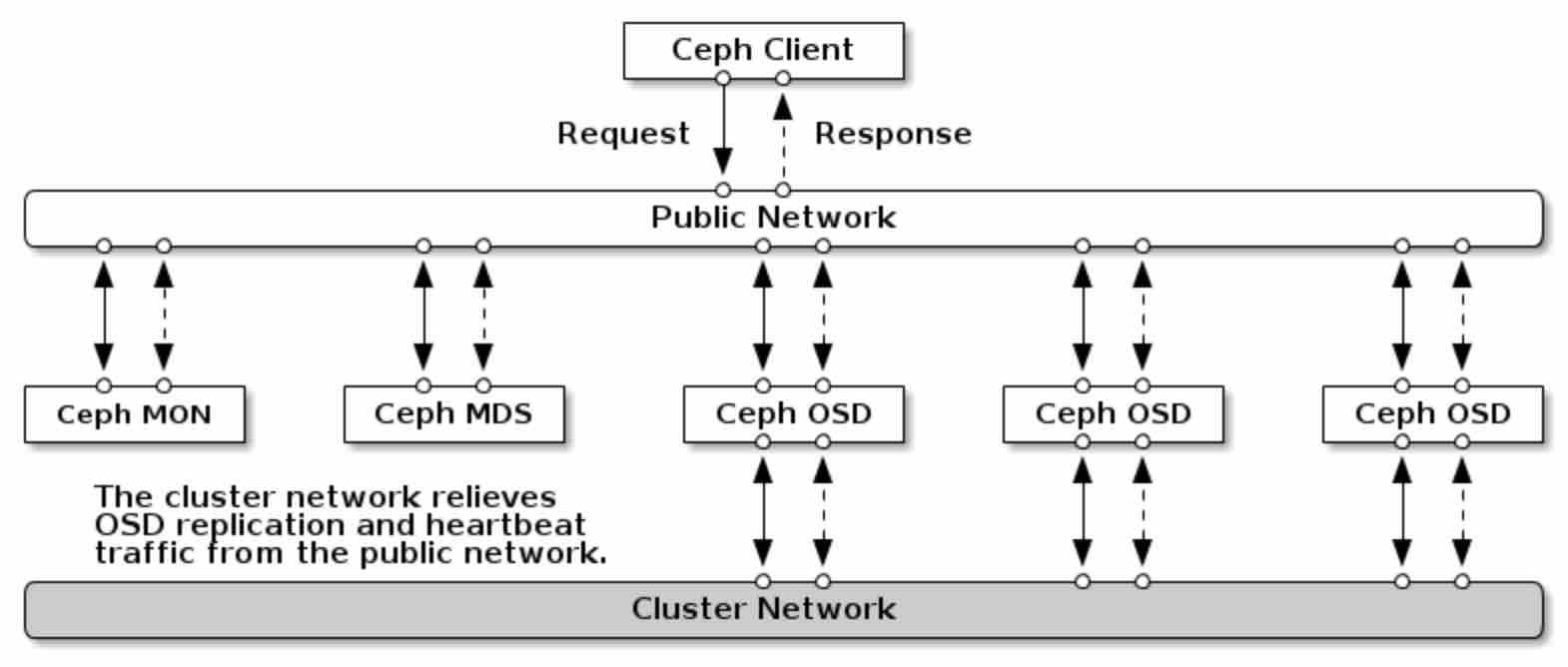
上图是ceph官方给出的系统部署图,从图中我们可以看到以下这此组件(简单地说,可将组件视为部署了不同ceph程序的服务器):
- Ceph Client(客户端),数据访问端点,其上部署了各种软件驱动(或库),最终为应用提供对象、块、文件服务
- Ceph Mon(Monitor),集群的管理者,负责维护集群状态图(如monitor map, OSD map, CRUSH map),并对客户端提供管理服务(客户端通过Monitor获取全局存储信息并建立访问连接);集群中通常有多个Monitor,以提升系统可靠性
- Ceph OSD(Object Storage Daemon),对象存储服务提供者,每个OSD提供数据存储空间、处理数据复制、恢复、均衡并通过彼此间的心跳机制为Monitor提供监控信息;一台配置了单独数据硬盘的服务器即可视为一个OSD节点;系统中通常也有多个OSD节点
- Ceph MDS(MetaData Server),为文件服务提供元数据管理功能;可选组件,在RBD中不涉及
- Public and Cluster Network,集群内部网络平面,Public平面提供客户端到集群的数据访问通信,Cluster平面为OSD之间的心跳和数据复制提供通信,采用两个独立的网络平面可以避免相互影响,提升系统整体服务性能
通过组件的协作,正常的数据流大体如下:
- Ceph Client通过驱动首先与Ceph Monitor建立网络连接,并完成认证,最后Ceph Monitor返回系统中所有的OSD状态图
- Ceph Client基于OSD状态图、访问对象和CRUSH算法计算出存放对象的主备OSD
- Ceph Client与主OSD(Primary OSD)建立连接并发起数据访问请求
- Primary OSD执行Client访问请求,对于写请求会将请求复制到其它备OSD(Replicated OSD),待其它OSD返回结果后再对Client返回执行结果
功能视角-ceph软件栈架构
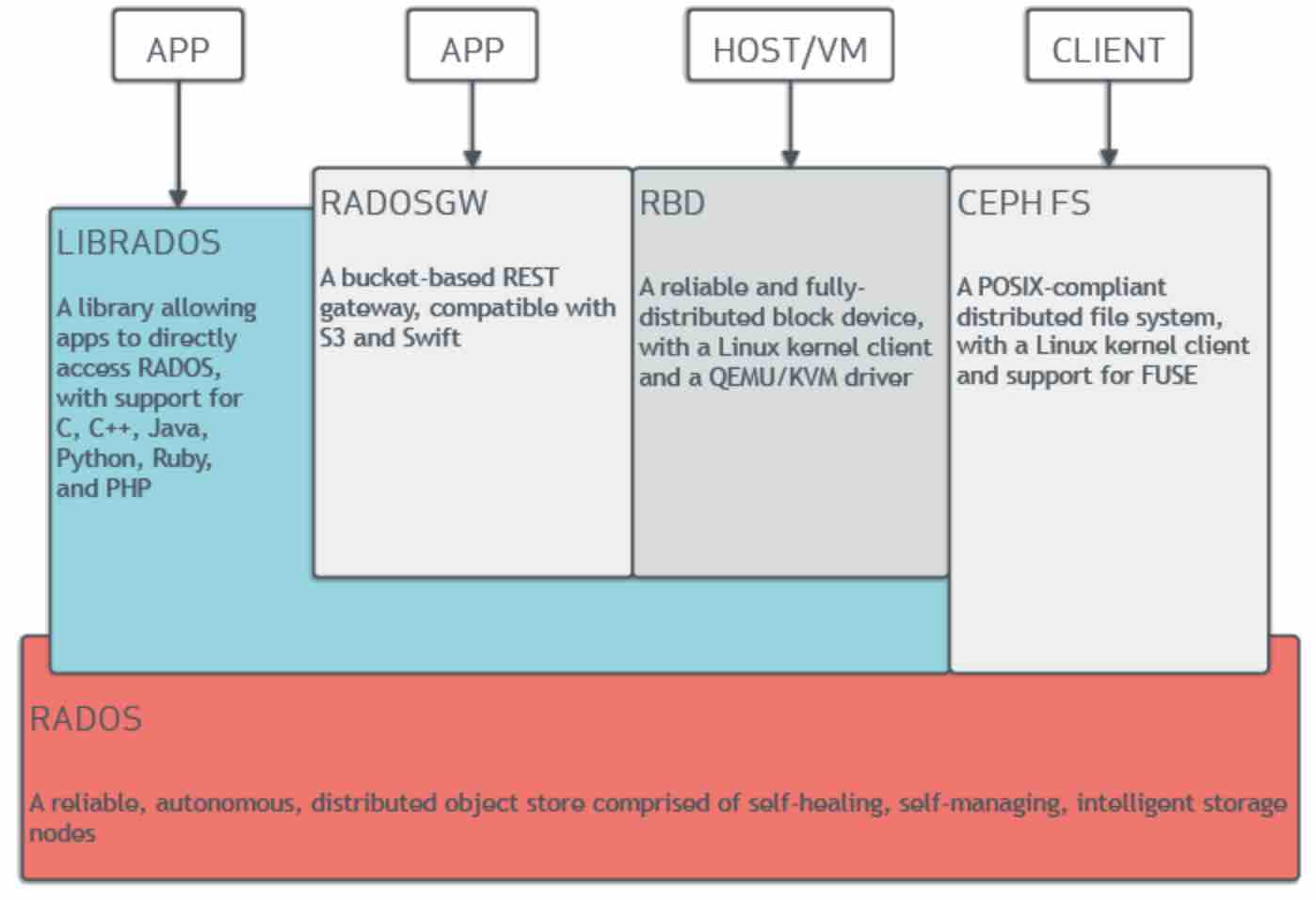
切换到功能视角,我们也可以看到ceph整体的软件栈架构:底部是由Monitor、MDS、OSD实现的Rados集群功能;客户端通过librados库为应用提供多语言的对象访问支持,或者通过RADOSGW实现兼客S3和Swift的对象服务,或者通过librbd库为应用(如虚拟化程序)提供块服务(也可通过内核RBD驱动实现),或者通过文件驱动为应用提供兼容posix标准的文件服务。注,RADOSGW和librbd基于librados构建,但内核块服务和文件服务直接在内核中实现,其中涵盖了librados的功能。
深入剖析
1. 数据对象映射与CRUSH算法
客户所见的RBD设备,在ceph内部存在多重映射,映射过程如下图所示:
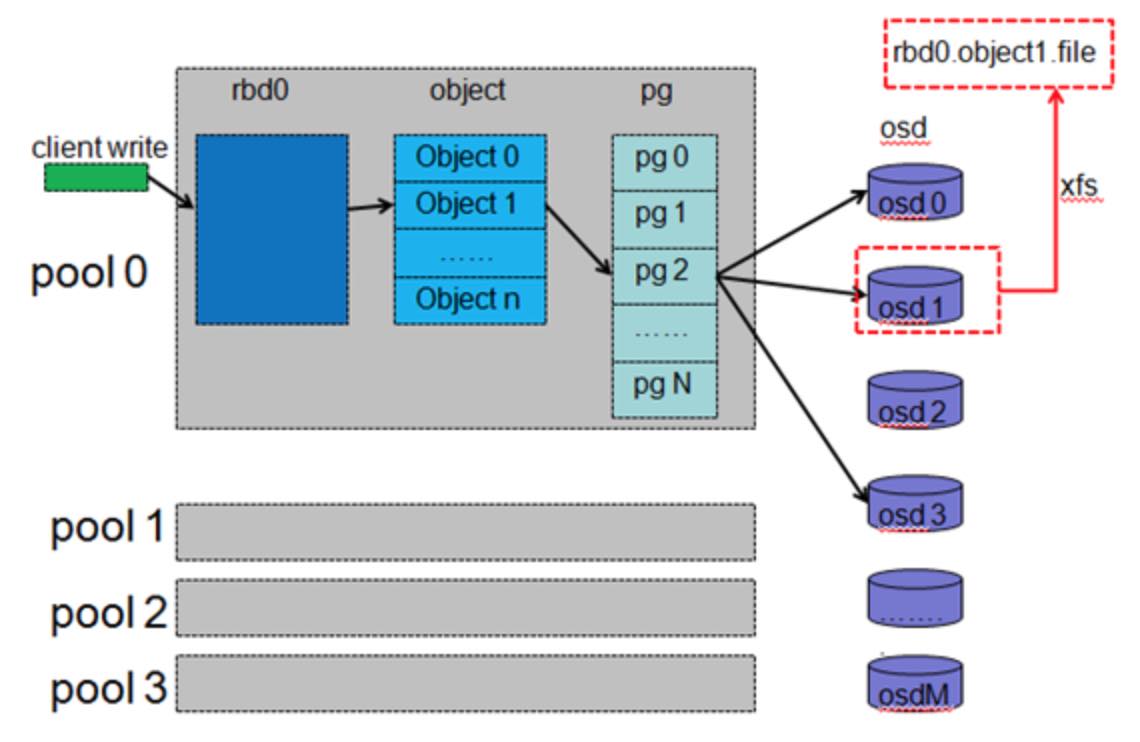
pool中的RBD设备首先按一定的粒度(通常为4M)划分成一个个对象,其命名方式为“rbd_id.偏移”形式;每个pool会定义一个pg(placement group)个数,接着每个对象被映射到pg中,映射方法为对象名的Hash值对pg数取余;然后每个pg通过CRUSH算法计算出一组存放该pg的OSD(第一个为主OSD,其它为备OSD),生成的OSD的数目由pool的数据复本数决定,例如三复本会生成三个OSD对象。每个OSD会在本地建一个存储池(例如一个XFS文件系统)用来存放映射到该OSD的pg,这些pg可以是源pg,也可以是复本pg。
ceph中更为一般的对象映射关系如下图所示:
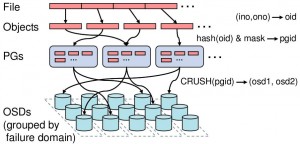
CRUSH作为对象映射的核心算法,依赖一个表达集群中所有OSD状态的OSD map,该信息由Monitors负责维护并在ceph各个节点间同步。
2. Client内核RBD驱动分析
我们可以将服务端(Monitor,OSD)当作黑盒来理解整个Client内核RBD驱动的工作原理:Monitor提供集群管理服务,OSD提供了对象数据访问服务。从软件栈上看,linux内核中的RBD驱动涉及上中下三层:
- 上层是在基于内核块层扩展的RBD驱动(rbd.ko),实现了一个新的RBD块设备;
- 中层是libceph驱动(libceph.ko),提供了数据分发服务(基于CRUSH)和访问Monitor及OSD的网络服务;
- 下层是内核网络socket层,提供POSIX接口的网络协议栈。各层核心对象概览如下:
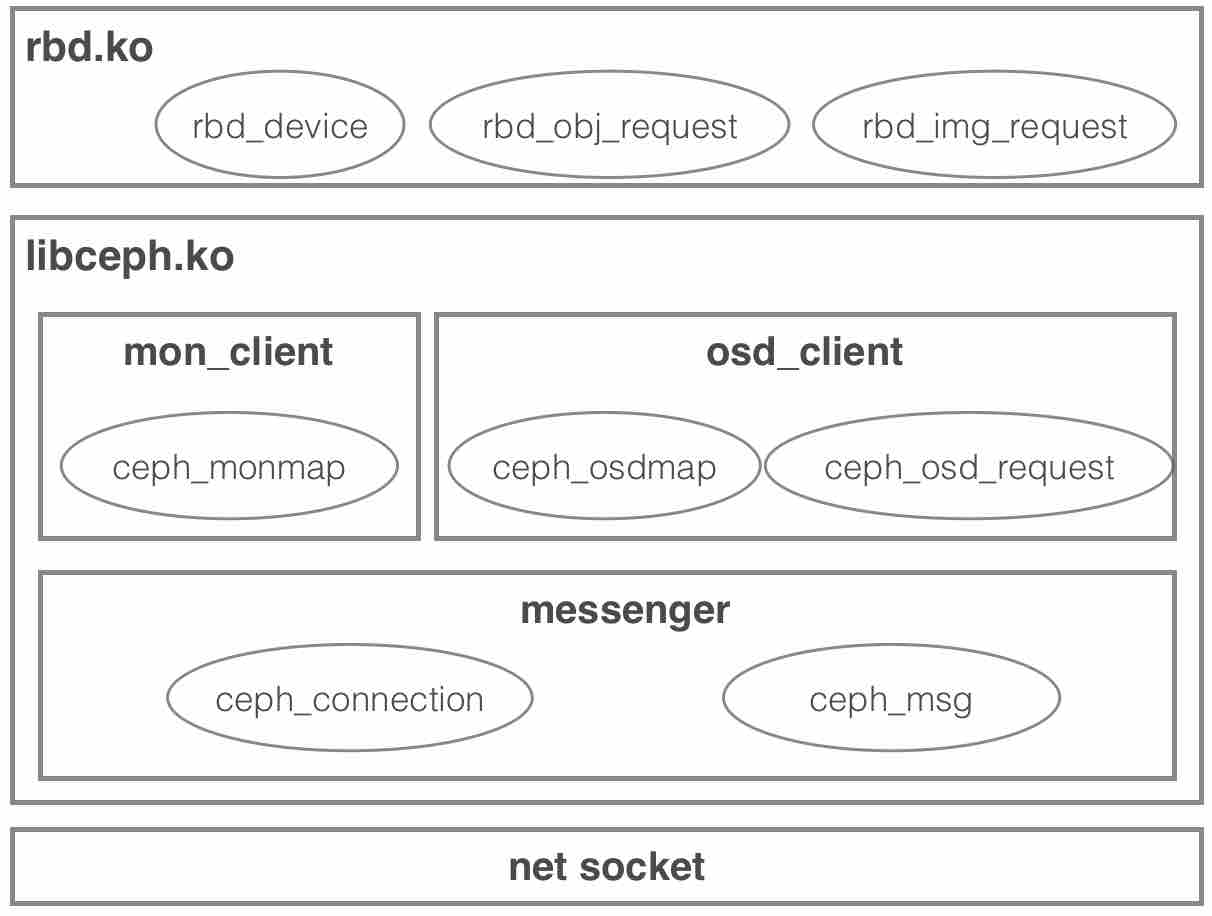
下面我们以操作流程为主要线索来深入分析RBD驱动原理,对于其中公共的网络部分我们将单独抽取出来进行分析:
3. ceph OSD原理分析
本节我们将打开服务端OSD进程,探索其内部实现原理。从软件栈上(下图)看,OSD服务分为四大模块:
- Messenger模块,和Client端的Messenger类似,该模块负责网络数据的收发,从接收消息的角度上来说,它处于业务逻辑的最上层。这里共有三种网络消息处理方式:SimpleMessenger是传统方式,支持POSIX接口;AsyncMessenger是新的异步处理方式,支持POSIX、RDMA、DPDK三种网络模式;Xio是一种实验性质的网络模式。
- OSD模块,请求处理的核心逻辑,内部通过PrimaryLogOSD进行本地PG的处理,并通过PGBackend与远端OSD进行通信以处理数据备份,这里的备份也有Replicated(复制)和EC两种模式。
- ObjectStore模块,最终实现PG的存储功能,支持FileStore、MemStore、BlueStore和KStore多种存储形式。
- Common模块,提供一些公共的类库(如thread、workqueue)给其它模块调用。
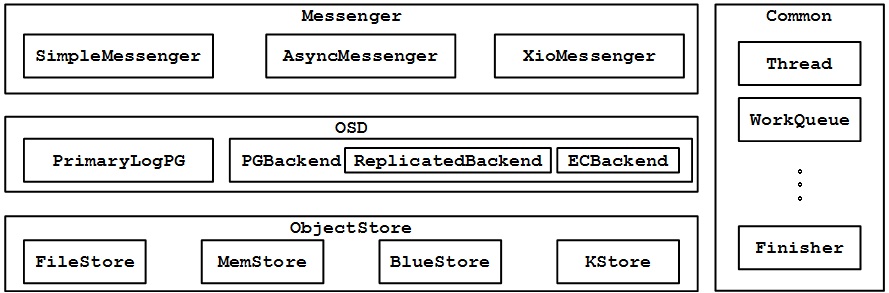
下面我们将分模块来分析OSD内部的请求处理过程:
4. ceph Monitor原理分析
Monitor虽说不是数据面的核心,但涉及整个集群的可靠性。这里我通过整理一些网上写得比较好的资料并加以补充,供大家学习时参考:
转载请注明:吴斌的博客 » 【Rados Block Device】一、概述