
从前面的博文分析中,我们知道OSD模块在请求处理的最后阶段会向ObjectStore发起操作请求,ObjectStore负责对象的实际存储功能,有filestore、bluestore、memstore、kstore等多种存储方式,这里我们以基本的filestore为例展开分析。
FileStore模块中对象、流程概览
我们照例先整体来看一下FileStore模块的对象和流程:
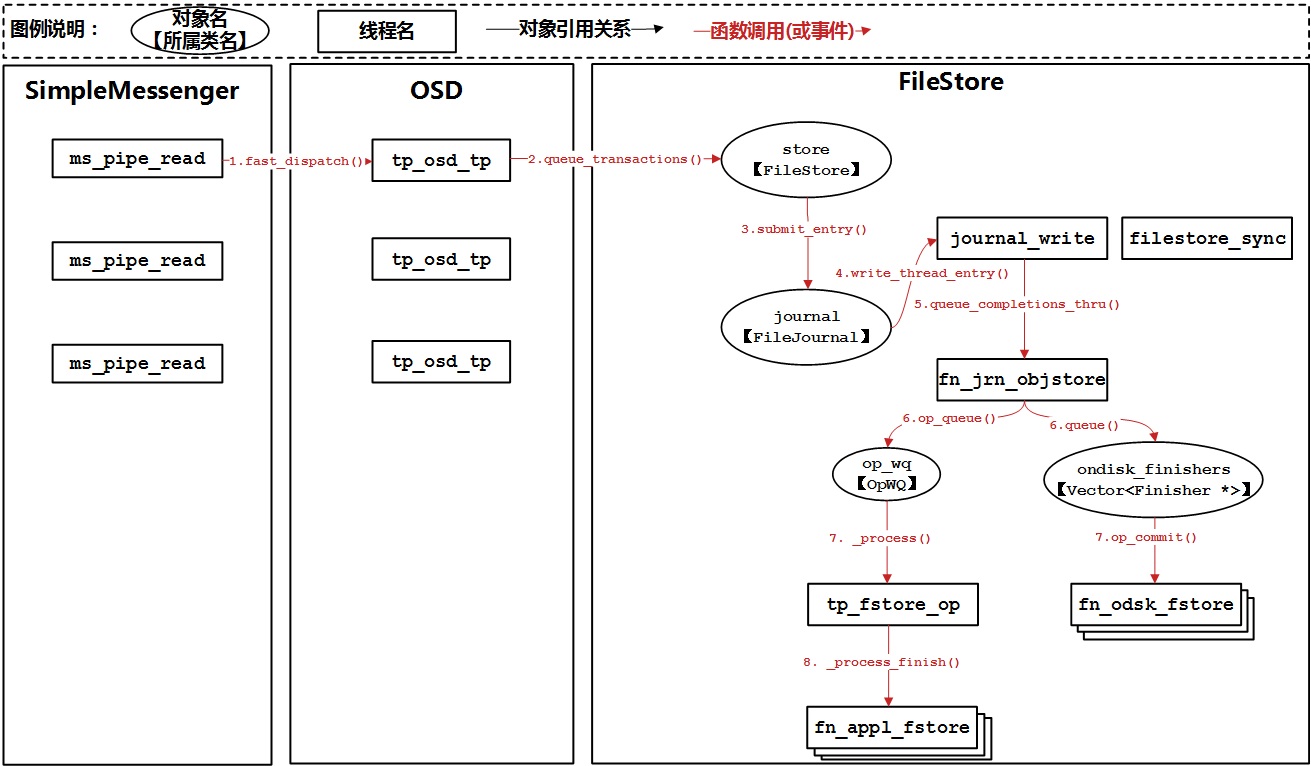
OSD模块在tp_osd_tp线程上下文的最后阶段,通过queue_transactions调用FileStore模块功能将操作请求以日志的方式提交到日志队列中,至此tp_osd_tp线程中的工作就完成了。后续由一个独立的日志写入线程journal_write从日志队列中取出操作日志并调用文件系统写入接口将日志操作写入实际的日志文件中(注,这里我们以journal ahead模式为例进行说明);日志写入完成后,通过queue_completions_thru接口将日志完成回调任务放入fn_jrn_objstorep线程的完成队列中。fn_jrn_objstore线程从完成队列中取出回调任务并立即调用回调,回调任务中会执行两个并发的子任务:一方面是通过op_queue将操作递交给OpWQ进行实际的数据落盘动作;另一方面是把OSD模块传入的回调任务放入fn_odsk_fstore线程池中进行处理。OpWQ队列对应tp_fstore_op线程,它会从队列中取出操作请求,并执行实际的数据落盘动作,落盘完成后再把落盘回调任务放入到fn_appl_fstore队列中进行回调处理。fn_odsk_fstore在处理OSD模块的回调任务时,会把OSD复本操作减一(因为写入日志后就认为本地写入操作完成了),如果远端OSD复本也完成了,那就会对客户端返回操作结果。此外,还有一个fileStore_sync线程负责日志空间的回收,便于重复使用日志文件。
FileStore模块中类的概览
下面我们来看看FileStore模块中涉及的主要类及其关系:
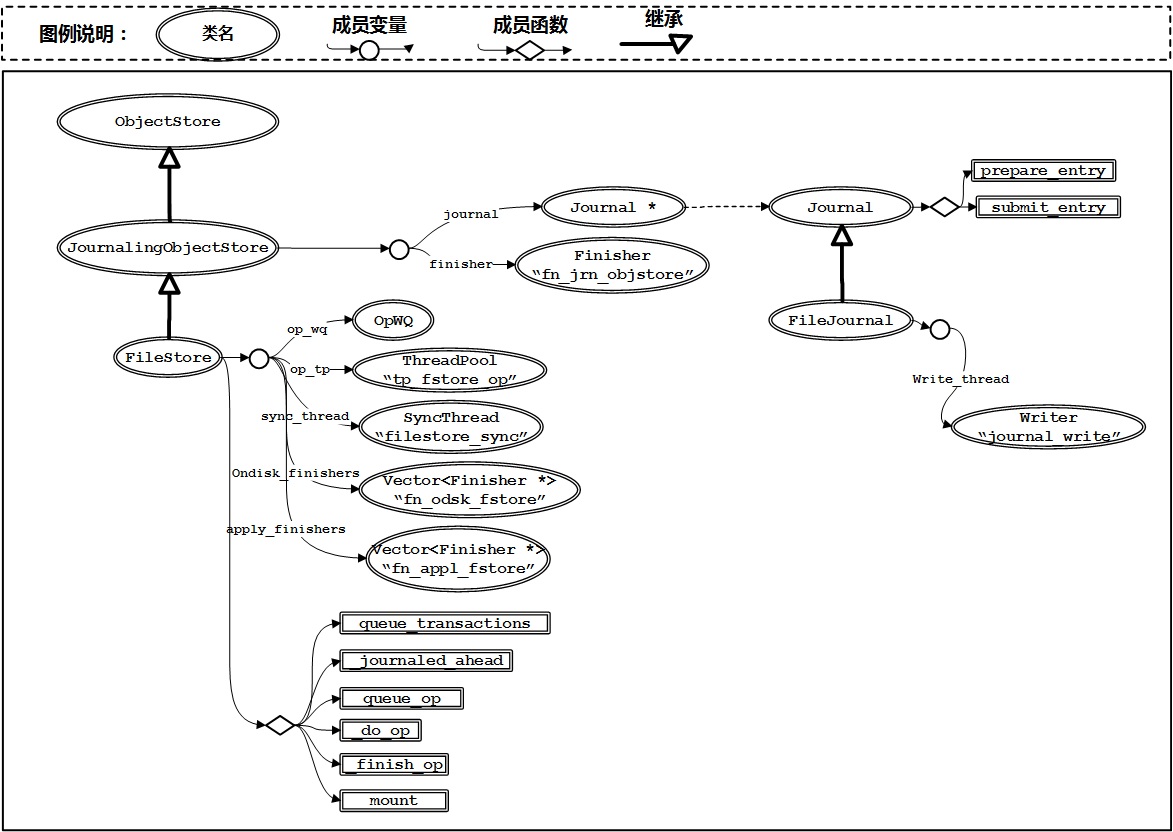
- JournalingObjectStore是FileStore的父类,继承自抽象父类ObjectStore。JournalingObjectStore包含一个Journal对象和一个Finisher对象,分别代表日志操作对象和日志操作完成后的回调对象。
- FileJournal继承了Journal类,以文件的方式实现了日志的主要操作功能。内部有一个专门的journal_write线程负责日志的落盘操作。
- FileStore是核心类,继承自JournalingObjectStore。OpWQ队列用来存放数据落盘请求,op_tp线程池会从该队列中取出请求执行落盘动作。sync_thread线程负责数据同步与日志空间回收。ondisk_finishers用来处理日志落盘后的回调;apply_finishers用来处理数据落盘后的回调。
代码详解
1. 初始化过程
filestore的初始化由FileStore::mount完成,其调用栈如下所示,大家可以自行展开阅读:
ceph_osd.cc:main()
\-OSD::init()
\-FileStore::mount()
2. tp_osd_tp线程上下文的日志提交
我们先来分析一下tp_osd_tp线程中的日志提交过程,其栈心处理函数为FileStore::queue_transactions:
FileStore::queue_transactions()
|-ObjectStore::Transaction::collect_context()
|-FileStore::build_op()
|-JournalFile::prepare_entry()
\-JournalingObjectStore::_op_journal_transaction()
\-JournalFile::submit_entry()
ceph/src/os/filestore/FileStore.cc:
int FileStore::queue_transactions(Sequencer *posr, vector<Transaction>& tls,
TrackedOpRef osd_op, ThreadPool::TPHandle *handle)
{
Context *onreadable;
Context *ondisk;
Context *onreadable_sync;
/*将所有事务中的回调分类进行汇总,onreadable代表on_applied,即数据落盘后的回调;
ondisk代表on_commit代表日志落盘后的回调;onreadable_sync代表on_applied_sync代表
数据落盘并同步完成后的回调*/
ObjectStore::Transaction::collect_contexts(tls, &onreadable, &ondisk, &onreadable_sync);
...
if (journal && journal->is_writeable() && !m_filestore_journal_trailing) {
/*封装一个新的操作op*/
Op *o = build_op(tls, onreadable, onreadable_sync, osd_op);
/*准备日志块内容,内部包含操作类型和操作数据*/
int orig_len = journal->prepare_entry(o->tls, &tbl);
/*OSD中对日志主要有两使用方式:parallel和writeahead。parallel代表日志落盘和数据落盘同时发起
writeahead代表日志先落盘,成功后再发起数据落盘。这里我们主要讨论writeahead模式*/
if (m_filestore_journal_parallel) {
...
}else if (m_filestore_journal_writeahead) {
/*提交日志到日志队列,并封装一个回调对象C_JournalAhead*/
_op_journal_transactions(tbl, orig_len, o->op,
new C_JournaledAhead(this, osr, o, ondisk), osd_op);
}
}
...
}
ceph/src/os/filestore/JournalingObjectStore.cc:
void JournalingObjectStore::_op_journal_transactions(
bufferlist& tbl, uint32_t orig_len, uint64_t op,
Context *onjournal, TrackedOpRef osd_op)
{
...
journal->submit_entry(op, tbl, orig_len, onjournal, osd_op);
...
}
C_JournaledAhead回调对象最终会调用FileStore::_journaled_ahead,代码如下:
ceph/src/os/filestore/FileStore.cc:
struct C_JournaledAhead : public Context {
FileStore *fs;
FileStore::OpSequencer *osr;
FileStore::Op *o;
Context *ondisk;
C_JournaledAhead(FileStore *f, FileStore::OpSequencer *os, FileStore::Op *o, Context *ondisk):
fs(f), osr(os), o(o), ondisk(ondisk) { }
void finish(int r) override {
fs->_journaled_ahead(osr, o, ondisk);
}
};
3. journal_write线程工作过程
tp_osd_tp线程将日志提交到日志队列是通过JournalFile::submit_entry实现的:
ceph/src/os/filestore/JournalFile.cc:
void FileJournal::submit_entry(uint64_t seq, bufferlist& e, uint32_t orig_len,
Context *oncommit, TrackedOpRef osd_op)
{
...
/*先在compleions列表中记录回调对象*/
completions.push_back(
completion_item(seq, oncommit, ceph_clock_now(), osd_op));
/*唤醒journal_write线程*/
if (writeq.empty())
writeq_cond.Signal();
/*将待提交日志放入日志队列writeq中*/
writeq.push_back(write_item(seq, e, orig_len, osd_op));
...
}
这里我们看看journal_write线程的工作原理,线程入口函数为FileJournal::write_thread_entry:
ceph/src/os/filestore/JournalFile.cc:
void FileJournal::write_thread_entry()
{
...
while (1) {
...
bufferlist bl;
/*从日志队列writeq中取出若干日志项*/
int r = prepare_multi_write(bl, orig_ops, orig_bytes);
...
/*将日志项写入到日志文件中,如果非direct io,会执行fdatasync;执行完成后将回调对象送入fn_jrn_objstore处理*/
do_write(bl);
/*记录日志写入完成事件*/
complete_write(orig_ops, orig_bytes);
}
}
4. fn_jrn_objstore回调
日志完全落盘执行的回调即是前文指出的FileStore::_journaled_ahead,它会触发两个并行的操作:
- 通过queue_op触发tp_fstore_op的数据落盘操作;
- 通地Finisher::queue触发OSD模块的回调
ceph/src/os/filestore/FileStore.cc:
void FileStore::_journaled_ahead(OpSequencer *osr, Op *o, Context *ondisk)
{
queue_op(osr, o);
if (ondisk) {
ondisk_finishers[osr->id % m_ondisk_finisher_num]->queue(ondisk);
}
}
5.(a) tp_fstore_op线程的数据落盘及fn_appl_fstore线程池的落盘回调
queue_op操作将落盘请求放入op_wq队列后,将由tp_fstore_op线程处理,该线程将周期性地调用_process和_process_finish函数:
ceph/src/os/filestore/FileStore.h:
struct OpWQ : public ThreadPool::WorkQueue<OpSequencer> {
FileStore *store;
...
void _process(OpSequencer *osr, ThreadPool::TPHandle &handle) override {
store->_do_op(osr, handle);
}
void _process_finish(OpSequencer *osr) override {
store->_finish_op(osr);
}
} op_wq;
FileStore::_do_op负责将数据落盘,FileStore::_finish_op负责将回调对象送入fn_appl_fstore线程池进入处理。
5.(b) fn_odsk_fstore线程池对OSD模块传入的日志落盘回调的处理
OSD传入的日志落盘回调对象为C_OSD_OnOpCommit,其实现代码为:
ceph/src/osd/ReplicatedBackend.cc:
class C_OSD_OnOpCommit : public Context {
ReplicatedBackend *pg;
ReplicatedBackend::InProgressOp *op;
public:
C_OSD_OnOpCommit(ReplicatedBackend *pg, ReplicatedBackend::InProgressOp *op)
: pg(pg), op(op) {}
void finish(int) override {
pg->op_commit(op);
}
};
void ReplicatedBackend::op_commit(InProgressOp *op)
{
/*将当前多复本操作等待对象中减去本地OSD,代表本地复本已完成*/
op->waiting_for_commit.erase(get_parent()->whoami_shard());
/*如果等待队列为空,表示远端OSD复本操作也完了,那就可以执行复本操作全部完成后的回调*/
if (op->waiting_for_commit.empty()) {
op->on_commit->complete(0); /*复本操作全部完成后将给客户端返回结果*/
op->on_commit = 0;
}
if (op->done()) {
assert(!op->on_commit && !op->on_applied);
in_progress_ops.erase(op->tid);
}
}