
什么是Virtio?为什么需要Virtio?
Virtio看字面是由Virt(Virtualization)和IO(Input/Output)两部分组成,含义是虚拟化环境下使用的IO协议/设备。早期在虚拟化技术的实现过程中,为了重用现有的设备驱动,虚拟化设备模拟软件一般都是模拟已有物理设备的行为(遵循物理IO协议),比如通过模拟IDE硬盘可以在虚拟机中完全重用IDE驱动。但是这里引发一个问题,模拟已有的物理设备行为往往导致虚拟化软件性能较低,比如IDE硬件是通过端口(Port)进行数据输入输出的,一段连续的数据需要大量端口操作才能完成。那么有没有可能引入一种新的协议标准,这种协议标准虽然在物理设备中是不存在的,但是可以提升虚拟化场景下设备对数据的输入/输出性能,并且具备一定的通用性,也就是说磁盘、网卡、显卡、键盘、鼠标等等设备都可以使用。
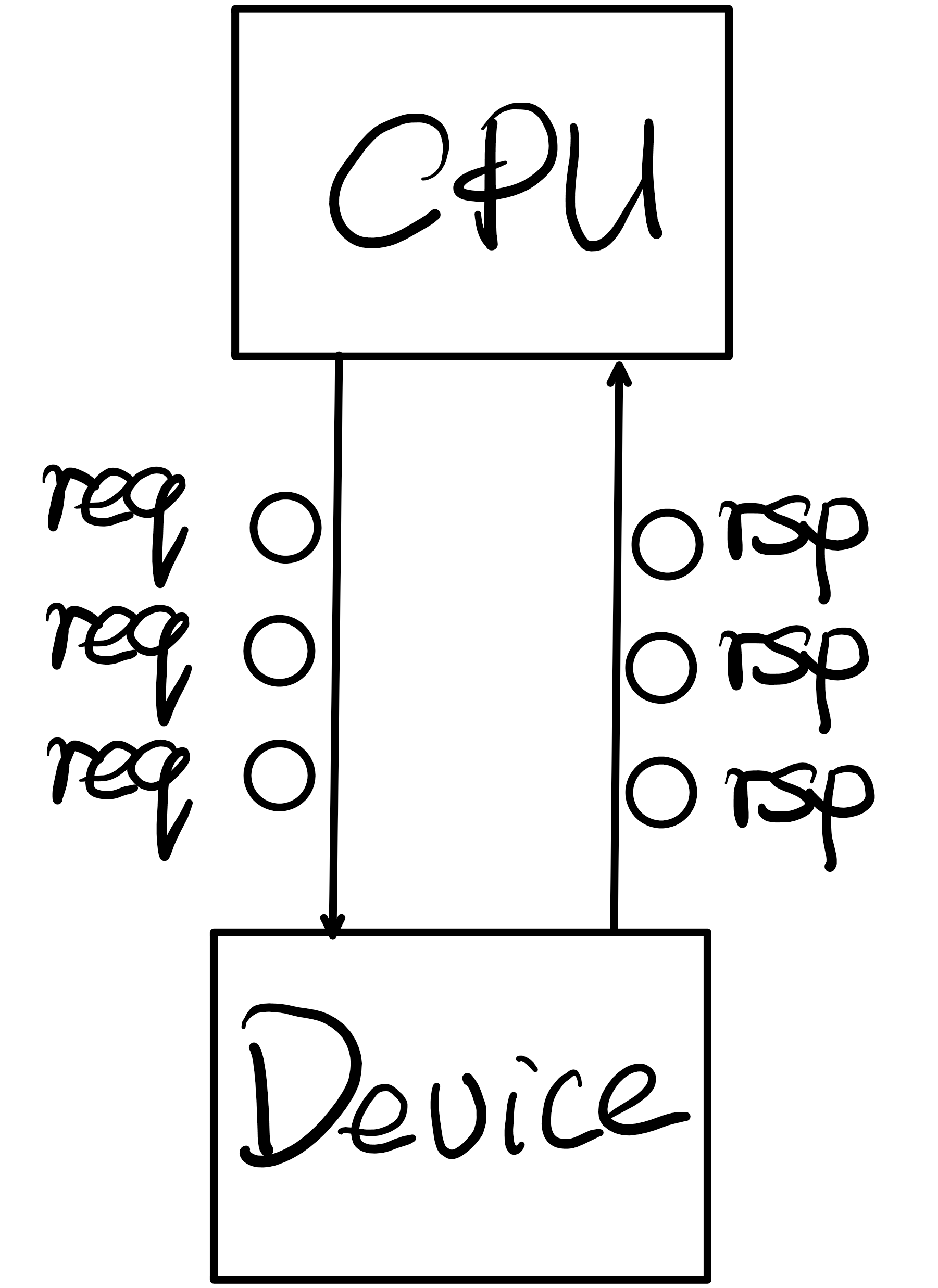
因此Virtio是在虚拟化场景中引入的一种高性能、通用IO协议,它可以让CPU批量地以队列方式向设备发送请求(Request)和输出数据(Output),当设备处理完成请求后,也可以让设备批量地以队列方式向CPU通知处理结果(Response)和输入数据(Input)。
如何自顶向下逐步实现Virtio?
从逻辑视角上分析,Virtio顶层所定义的CPU和设备之间批量请求、结果和数据的传输功能是非常基础的能力,无须进一步展开。我们可以在生活中找到非常多类似的例子,比如项目经理通过电话或邮件向项目成员发送了一系列任务,项目成员完成任务后,又通过电话或邮件向项目经理知会完成情况。那么实现Virtio重点就是从物理视角进行展开。
整体IO处理流程设计
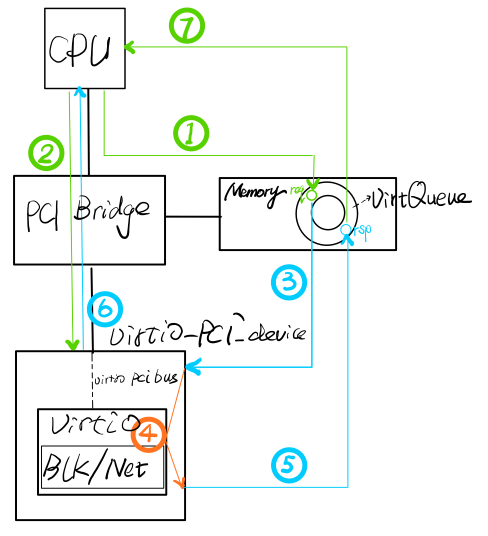
从物理视角展开分析之前,我们先要了解CPU与设备之间的IO传递是建立的更基础的总线协议之上,它的作用这就好比上面例子中的电话或邮件。以PCI标准总线为例,通过PCI桥可以将设备中的寄存器或存储器映射到CPU可见的内存地址空间中,CPU通过执行对这些地址空间的内存读/写指令就可以完成对设备中寄存器的读/写操作(内存读/写指令会由PCI桥完成,PCI桥根据访存地址决定是发送给物理内存,还是通过PCI总线发送给设备);反过来,设备也可以通过PCI总线访问物理内存(DMA)或者发送中断通知给CPU(MSI/MSIX)。除了PCI总线,Virtio协议也可以构建在其它总线类型上(如MMIO总线),它们的作用都是类似的,就是让CPU可以访问设备寄存器、让设备可以访问物理内存并通知CPU有事件发生。
理解PCI总线机制后,我们就可以设计出物理视角上的项层IO处理流程,这里以单个IO进行示意:
- CPU将IO请求放入内存请求队列中(请求队列就是存放请求的地方,这样可以批量、异步地发送请求);
- CPU通过写设备中特定的寄存器唤醒设备并通知它有IO请求待处理;
- 设备被唤醒后通过DMA操作从内存请求队列中取出IO请求;
- 设备将IO请求交给内部核心处理逻辑进行处理,比如交给块设备(Blk)通过DMA进行数据存取或者网络设备(Net)进行数据收发;
- 设备处理完成后将IO响应放入内存响应队列;
- 设备以中断方式通知CPU有IO响应待处理(表示IO请求处理结果);
- CPU在中断上下文中从IO响应队列中取出IO响应进行处理,并最终告知应用程序IO处理结果。
这里有一个设计选择问题就是请求队列和响应队列为什么要放在物理内存中?从实现上说,请求队列和响应队列也可以放到设备的寄存器或存储器中,这样CPU在放入请求或者设备在放入响应时,就可以一步到位,不用通过内存作为中转。实际上,当放入请求动作对应的数据写入量不大的时候(也可能是取出响应动作对应的数据读操作),的确可以提升放入请求动作的性能,但此时CPU是处于Stall状态直到写入操作完成。那么当放入动作对应的数据写入量较大时,CPU就会长时间处于Stall状态,导致CPU计算效率变低。所以Virtio协议在设计时选择将队列置于物理内存中而不是直接放在设备中,而有些协议(如NVMe)选择同时支持两种方式。
队列数据结构设计
从顶层IO处理流程上看,CPU和设备都是基于内存进行读写操作从而完成请求和响应的传递,那么我们该如何设计内存中队列的数据结构?这是Virtio协议设计中最为关键的展开环节。
首先,既然是队列,最合适的数据结构是数组,那么数组元素该如何设计?数组元素代表的是每个IO请求、数据或者IO响应,而对于不同类型的设备(磁盘、网卡等等),请求、数据或响应的内部结构又是不相同的。我们可以观察到无论什么样的请求、数据或响应,从结构本质上看,都是由一段或几段连续内存组成的,每段连续内存由起始地址和长度两个要素决定。这样我们就可以设计一个数组,数组中的元素包含两个成员:起始地址和长度,每个IO可以对应若干数组元素。
为了重复使用队列内存空间,通常会以环形方式使用数组元素,即已经处理完成的IO对应的数组元素可以用来存放新的IO。但是IO完成的顺序和IO放入的顺序并不完全一致,先取出的IO可能最后才完成,且每个IO对应的元素个数也不相同,这就导致空闲的数组元素并不完全连续。一个可行的解决思路就是采用链表结构来链接各个元素,元素在数组中的位置可以不连续。除了链表,还有没有其它解决思路?如果每个IO就对应一个数组元素,不连续也没啥问题,那就不用链表了,这个思路在Virtio中对应的就是Indirect特性,这里暂不展开分析。
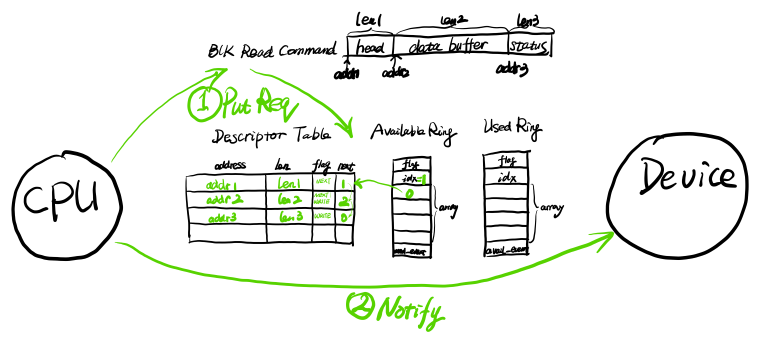
这样我们就有了一个基本的数组结构,用来表示每个IO对应的请求、数据和响应,这就是Virtio中的Descriptor Table,如下所示(flag的作用后续说明):

接下来要考虑的问题就是当CPU把一个IO包含的请求、数据、响应对应的内存信息以链表方式填入Descriptor Table中后,那么怎么让设备知道当前有多少个IO并且知道每个IO链表的确切元素?一个解决思路就是设置一个计数变量和一个链表头数组,计数变量用来表明当前共有多少个IO,而链表头数组用来表明每个IO对应的链表头在Descriptor Table中的位置,这就是Virtio中的Available Ring。同样,当IO完成时,设备也需要让CPU知道共有多少个完成的IO和每个IO链表的确切元素,这就是Virtio中的Used Ring,如下所示:

数据结构设计另外一个要考虑的重要问题就是并发操作时的数据同步难题,通常情况当涉及多个CPU同时操作相同数据结构时会采用锁机制进行同步,但是在CPU和设备间无法直接采用锁机制进行同步。这里采用的是无锁队列的设计模式,相同的内存区域只有一方有写入权限,不允许CPU和设备同时写入。Virtio设计中,Descriptor Table和Available Ring只有CPU有写入权限,而Used Ring只有设备有写入权限。更进一步,当CPU向Available Ring放入请求而设备从中读取,或者当设备向Used Ring中放入响应而CPU从中读取时,要正确使用内存栅栏,因为Available Ring的idx和数组内容存在逻辑依赖,即先更新数组再更新idx。
队列操作实现细节
完成数据结构设计后,我们就可以总结每个IO步骤对应的实现细节,这里我们以向Virtio-Blk设备发送一个读取命令为例进行说明。
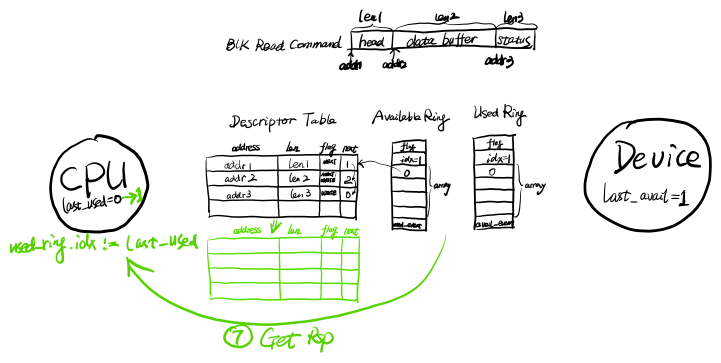
首先,CPU放入IO请求并通知设备:CPU发起的对Virtio-Blk的读IO操作在内存对应三段内存,分别是head、data buffer和status。head表示操作类型(这里为读操作,也可为写操作)、起始扇区和数据长度,data buffer是存放从设备中读取的数据的内存区域,status表示IO操作结果(0代表成功)。对于读操作来说,head由CPU写入,data buffer和status由设备写入,因此我们在Descriptor Table中申请空闲三项元素,依次填入内存地址和长度,并组成链表。flag标志位的NEXT标志代表存在下一项,WRITE标志代表由设备写入。然后将Available Ring中数组下标为idx(当前为0)的元素更新为Descriptor Table中IO链表头部元素的下标,放置写栅栏,随后再更新idx为1,代表有新的IO待处理。接着通过总线提供的通知机制,通知设备有IO待处理,例如PCI总线的MMIO机制。过程如下图所示:
其次,设备取出IO请求并处理:设备内部通过last_avail变量记录当前已经处理的IO请求位置,初始为0。设备被唤醒后,通过对比Available Ring中的idx(此时值为1)和last_avail来确定是否有未处理的IO请求,两者不一致则表示有IO请求未处理。然后放置读栅栏(对应CPU放置的写栅栏),之后以last_avail对数组长度取余后的结果为索引去读取Available Ring中数组元素的值,该值代表IO链表头部元素在Descriptor Table中的位置。通过链表头我们就可以从Descriptor Table中找到IO对应的所有内存段,就可以还原完整的IO结构。取出IO请求后设备便将last_avail变量加1,此时等于Available Ring的idx,表示IO请求已全部取出。取出的IO请求交给设备中的Blk模块执行真正的读取动作,把数据和读取结果通过DMA写入到data buffer和status中。过程如下图所示:
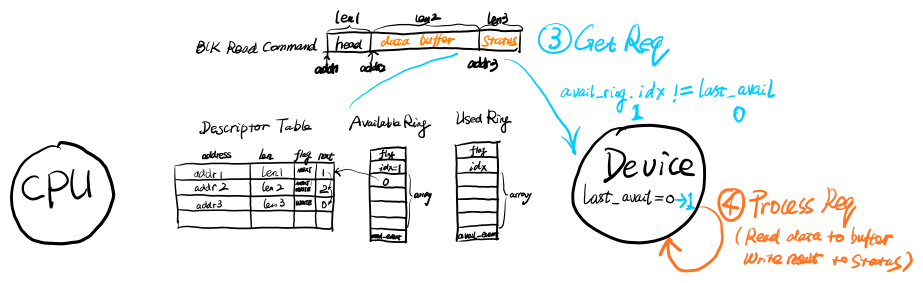
接着,设备放入IO响应并通知CPU:设备完成IO操作后,将完成IO链表头部元素在Descriptor Table中的下标位置写入Used Ring的数组中,放置写栅栏,并将Used Ring头部idx值由0更新为1,表示有一个IO响应待处理。然后设备通过中断方式通知CPU处理。过程如下图所示:

最后,CPU取出IO响应并处理:CPU内部通过last_used变量记录当前已经处理的IO响应位置,初始为0。被设备中断后,通过对比Used Ring中的idx(此时值为1)和last_used来确定是否有未处理的IO响应,两者不一致则表示有IO响应未处理。然后放置读栅栏,之后以last_used对数组长度取余后的结果为索引去读取Used Ring中数组元素的值,该值代表IO链表头部元素在Descriptor Table中的位置,此时为0。IO响应取出后,CPU将last_used变量加1,然后将IO链表元素进行释放重新作为空闲Descritptor Table项。过程如下图所示:
如何优化设计并提升代码实现质量?
如果只想了解Virtio基本原理,读到上一章节就足够了,再结合开源QEMU代码实现,应该有一个全面且深入的理解了。但是如果要高质量地实现Virtio,还需要从非功能的质量属性(性能、成本、扩展性、维护性、可靠性/可用性、安全性、韧性等)维度进行思考,这里Virtio设计比较相关的是性能、可靠性/可用性。
所有前期设计工作关注的要点都是功能如何实现,就像我们前面所做的一样。当功能设计细化到一定程度的时候,我们就需要回过头来通盘考虑系统性能要素和可能的优化思路。Virtio关注的性能要素主要是IO处理时长,我们前面分析的队列存放位置也包含对性能的考虑,另外一个Virtio关注的性能场景是CPU和设备之间的通知开销,每放入一个IO请求,CPU都可以通知一次设备,也可以放入一批再通知;设备如果一直处于取请求的状态,那么CPU新放入一个请求后是不是就可以不通知设备了?这些问题都是在考虑如何尽可能少地引入CPU和设备间的相互通知动作,提升IO吞吐。这就是Virtio引入event_idx特性的背景,详细的实现思路大家可以自行分析。
除了性能,提升可靠性/可用性重要的设计考量就是对异常场景的处理,这也是在功能设计过程中容易被忽视的环节。比如前面对队列结构进行操作时,CPU和设备都是按正常操作进行的,如果CPU对队列结构进行恶意、非常规操作,会引发设备侧怎样的后果?从Descriptor Table看,如果元素的addr超过了最大物理内存,设备直接用这个addr访存会越界;如果next链成了环,那设备可能死循环读取无法正常结束;如果next超出了数组大小,那设备可能读到随机值。再从Availalbe Ring看,如果放入数组的IO链位置超过Descriptor Table大小,那设备也可能读到错误的IO请求;如果idx随意设置,如设了一个过大值,那设备可能一直尝试读取IO请求,且这些IO请求内容是无实际意义的。因此我们看到异常场景识别的充分程度决定了代码质量,很多实际使用中遇到的问题都是源于设计/开发者对非常规场景识别的不足。查看QEMU代码中Virtio的实现部分,我们也会发现异常分支的处理占了总代码量(1万行左右)的一半以上,足以说明异常处理的复杂性和重要性。
最后总结一下写这篇博文的动机,Virtio是虚拟化领域非常重要的技术成果之一,一方面很多初学者对它的技术原理总是一知半解,并不系统和全面,另一方面资深老铁们(包括我自己:>)出于各种原因会想着自己实现一把Virtio,但是多少都会遇到原型跑通容易、真正能用难的困境。分享出我们的设计收获,期望更多的虚拟化技术爱好者能真正理解现有的开源代码,当历史机遇到来的时候也能设计并创造领先世界的新技术,也欢迎大家一起参与到openEuler社区虚拟化项目StratoVirt中,跟我们一起重新发明轮子,Enjoy Hacking Virtualization!
转载请注明:吴斌的博客 » 自顶向下设计与实现Virtio