
编程模型(Programming Model)与执行模型(Execution Model)
前文分析CUDA原理时介绍了CUDA的编程模型,它是对硬件的抽象,作用是便于开发人员将逻辑思维过程转换为计算系统的物理运行过程。CUDA内部实现非常复杂,基础编程模型可以方便地表达并行性,但是在性能上暴露的细节不多,因此有可能无法充分发挥硬件潜能。正因如此,CUDA引出了执行模型的概念,进一步向开发者暴露设备内部执行细节,并提供性能分析工具和API,使得开发者可以调试应用性能。
CUDA执行模型中包含了整个设备、SM (Streaming Multiprocessors)和计算核 (Core),它们与编程模型对应关系如下图所示:逻辑模型中的每个线程均运行在计算核上,线程块整体运行在SM上,而整个核函数运行于设备上。

结构与执行流程剖析
物理结结上我们看到CUDA GPU的内部结构如下图所示:设备内包含内存(DRAM)、任务引擎(Giga Thread)、L2缓存和大量SM计算单元。

GPU内部的SM进一步打开如下图所示:SM内包含warp调度引擎(warp Scheduler)、指令发射器(Dispatch Unit)、大量寄存器、计算核、Load/Store Unit、SFU(Special Function Unit)。
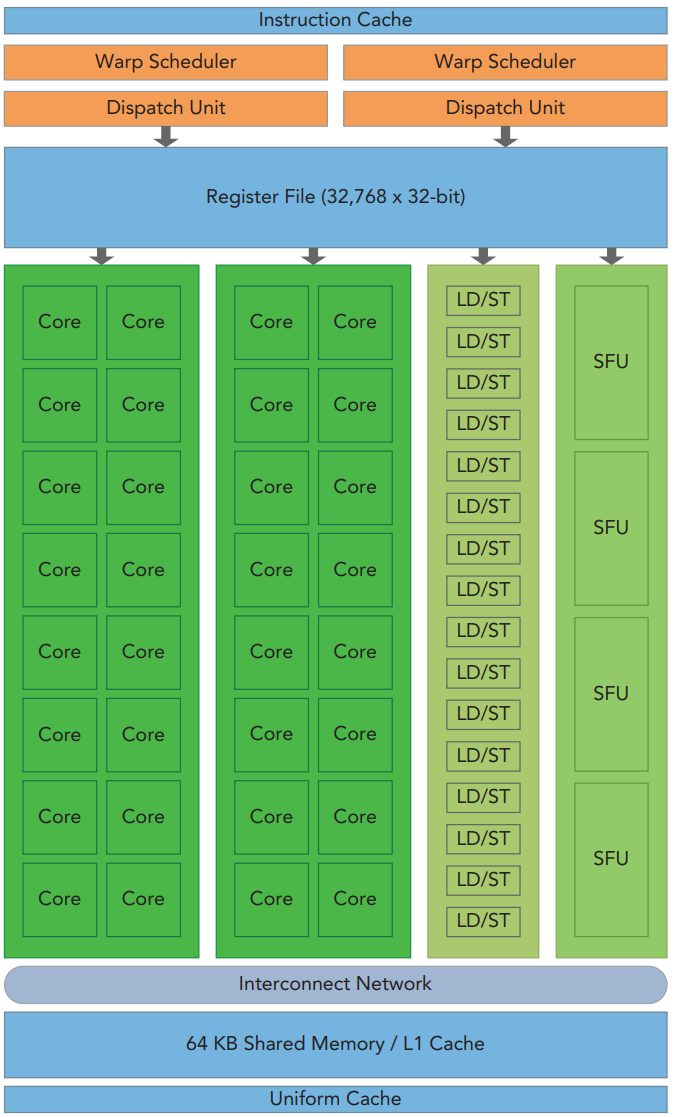
一个核函数的执行过程如下:
- CPU通过CUDA驱动将核函数相关信息经过总线(如PCIE)发送给CUDA设备;
- 设备接收核函数后通过任务引擎(Giga Thread)将核函数的各个Block发送到不同的SM上执行,Giga Thread起到了顶层Block调度的作用(调度细节没有相关资料可查阅);
- SM接收到Block后,将它以32个线程为一组为成多个warp,warp是SM内的执行单元。warp由SM内的warp调度器进行调度(同样没有太多关于warp调度器的细节资料),一旦某个warp获得调度执行,它将交由指令发器下发给真正的执行体进行计算或数据传输,如计算核进行整数或浮点运行、SFU进行正弦函数计算、L/S Unit进行地址计算等等;
- 当所有Block均执行完成后,由设备发送中断通知CPU计算任务完成;
了解CUDA的执行模型后,我们可以通过工具获取当前运行GPU的结构参数,如SM个数、SM中计算核个数等等,而后通过设置合理的Grid和Block维数就能充分发挥硬件能力,例如对于有多个SM的GPU,如果只设置一个Block,那么所有逻辑线程只能在一个SM上执行,其它SM就浪费了。
CUDA对于执行模型的暴露可能也是一种不得已而为之的策略,未来如果能做到基于高阶抽象编程模型自动进行性能优化那将是一个非常有竞争力的系统。