
地址映射是CPU核心和MMU共同完成的内存管理功能之一,本节将对此展开深入讨论。计算子系统相关内容目录点此进入。
什么是地址映射?为什么需要它?
正如在计算机系统整体介绍中所说明的一样,MMU在CPU的配合下(通过页异常触发),实现了线性地址到物理地址的动态映射,为正在CPU上运行的应用程序(进程)提供了一个独立的连续内存空间(线性地址空间,或称虚拟内存空间,其中放置了代码段、数据段和堆栈段),屏蔽了地址分配、内存分配和内存回收等一系列复杂的系统行为,不仅提升了内存资源的利用效率,而且大大降低了应用开发难度,使程序猿可以更聚焦业务逻辑。结合CPU的进程管理功能,可以实现一个多任务并行系统,提升系统的可用性和性能。
如何实现?
1.线性地址
x86_64架构下Linux中每个应用程序(进程)可见的线性地址空间如下(注:分段机制在64位模式下已不产生实际作用):
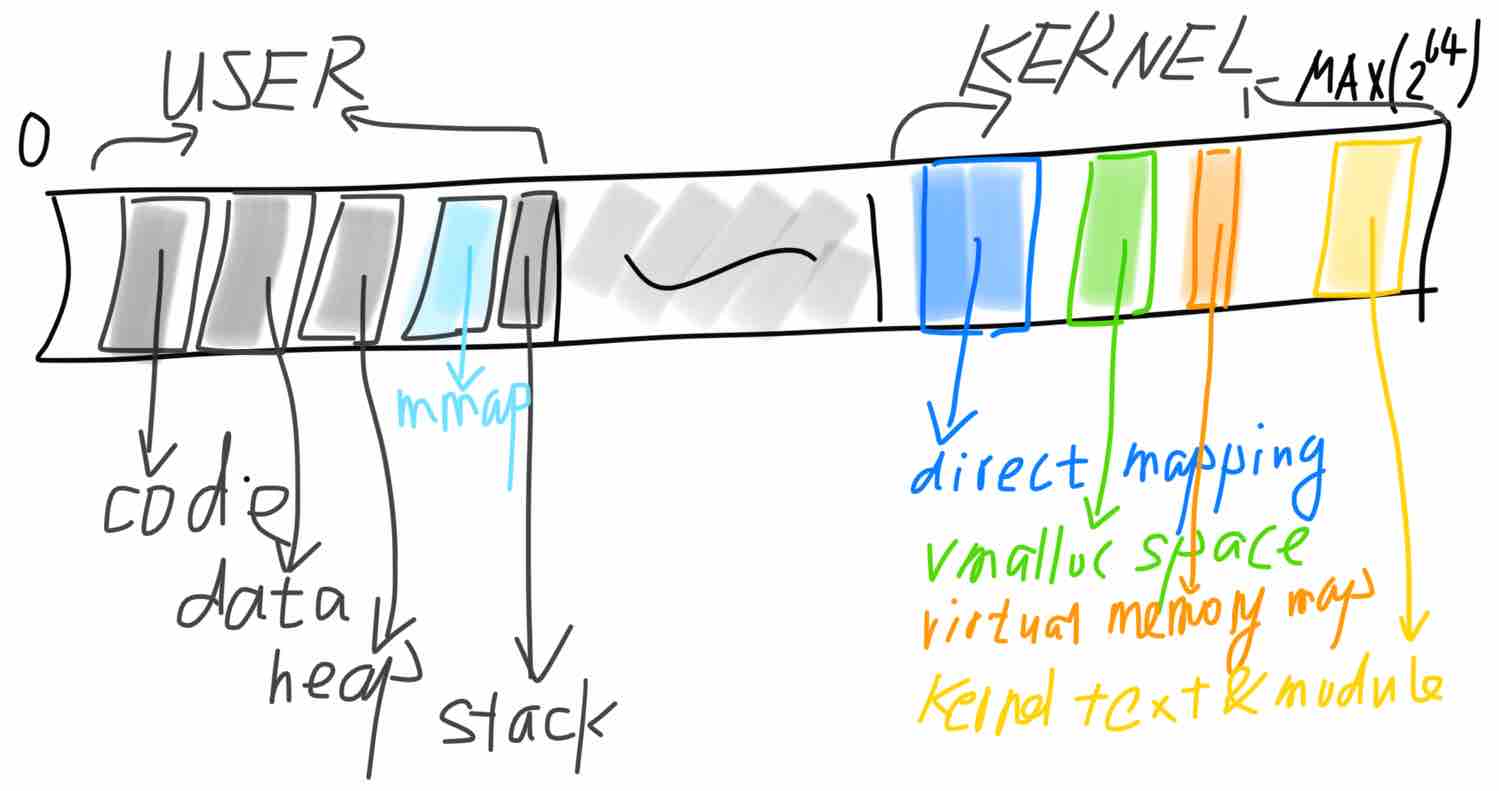
该架构支持48位线性地址(高16位仅做符号扩展,不参与地址转换)到40位物理地址(最多52位,由CPU实现决定)的映射。48位线性空间共256T,分为两个128T区间,分别分布在完整的64位空间的两端。其中,低128T为用户空间,映射用户程序代码、数据、堆栈和共享库,物理内存随着程序的运行由内核动态分配。而高128T则为内核空间:direct mapping区映射整个物理内存空间,便于内核访问所有物理内存;vmalloc space区间为内核调用vmalloc时使用的线性空间,物理内存动态分配且物理上不保证连续;virtual memory map是内核标识内存页信息的数组,供内存管理功能使用;kernel text & module区存放内核和模块的代码及数据。此外,也可以参考内核代码的说明:
linux/Documentation/x86/x86_64/mm.txt:
0000000000000000 - 00007fffffffffff (=47 bits) user space, different per mm
hole caused by [48:63] sign extension
ffff800000000000 - ffff80ffffffffff (=40 bits) guard hole
ffff880000000000 - ffffc7ffffffffff (=64 TB) direct mapping of all phys. memory
ffffc80000000000 - ffffc8ffffffffff (=40 bits) hole
ffffc90000000000 - ffffe8ffffffffff (=45 bits) vmalloc/ioremap space
ffffe90000000000 - ffffe9ffffffffff (=40 bits) hole
ffffea0000000000 - ffffeaffffffffff (=40 bits) virtual memory map (1TB)
... unused hole ...
ffffff0000000000 - ffffff7fffffffff (=39 bits) %esp fixup stacks
... unused hole ...
ffffffff80000000 - ffffffffa0000000 (=512 MB) kernel text mapping, from phys 0
ffffffffa0000000 - ffffffffff5fffff (=1525 MB) module mapping space
ffffffffff600000 - ffffffffffdfffff (=8 MB) vsyscalls
ffffffffffe00000 - ffffffffffffffff (=2 MB) unused hole
2.地址转换
MMU的线性地址转换是通过页表进行的,具体过程如下图所示(摘自intel程序员手册卷3):
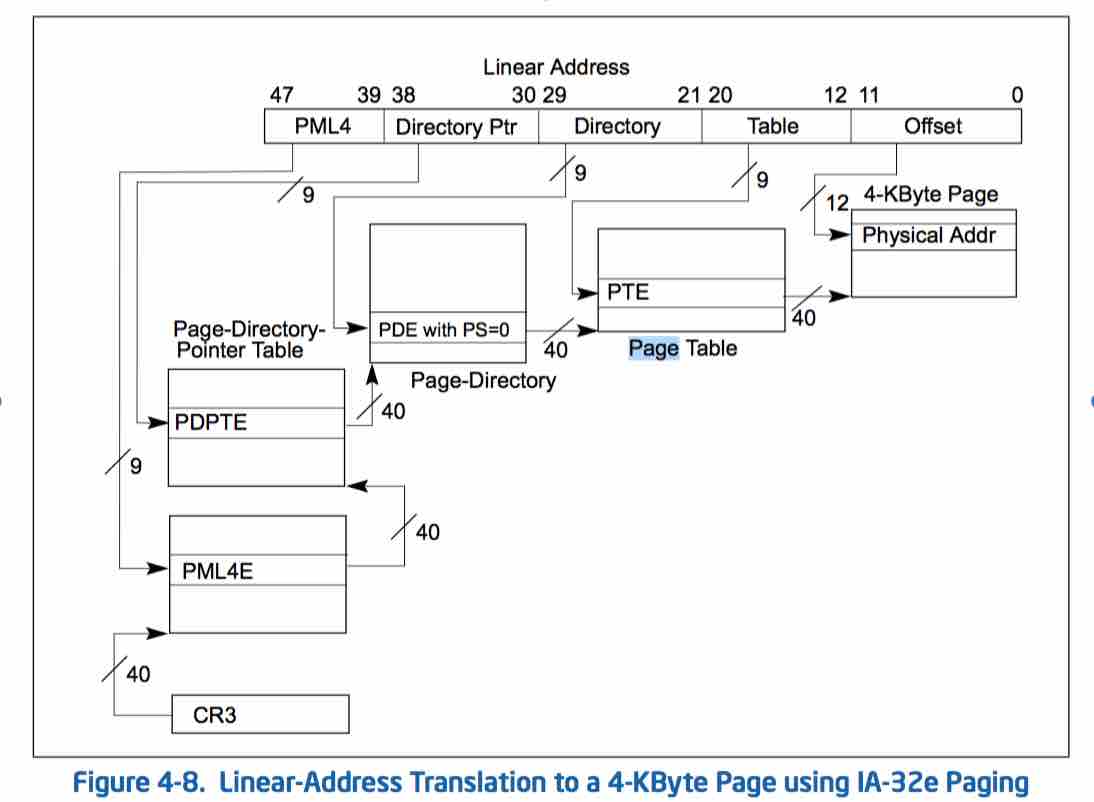
其实最简单明了的方法是通过一个一维数组来记录映射关系:下标代表线性地址,数组元素内容代表物理地址。可是如此一来,用来表示映射关系的内存空间比被表示的物理空间还要大,显然这不是一个可行的方案。
工程师们采用了分段分级的思路来表示这种映射关系:先把线性空间以4K大小为单位进行划分(页),然后再以大段连续空间进行转换,在每个大段空间内部再次划分成小段进行转换,直到段大小变为4K页大小。用以表示和段空间映射关系的结构称为页表,其大小也是一个页面。由于采用了分段的方法,页表空间大大减小;同时未映射的空间不必分配页表,这也进一步降低了页表占用空间。
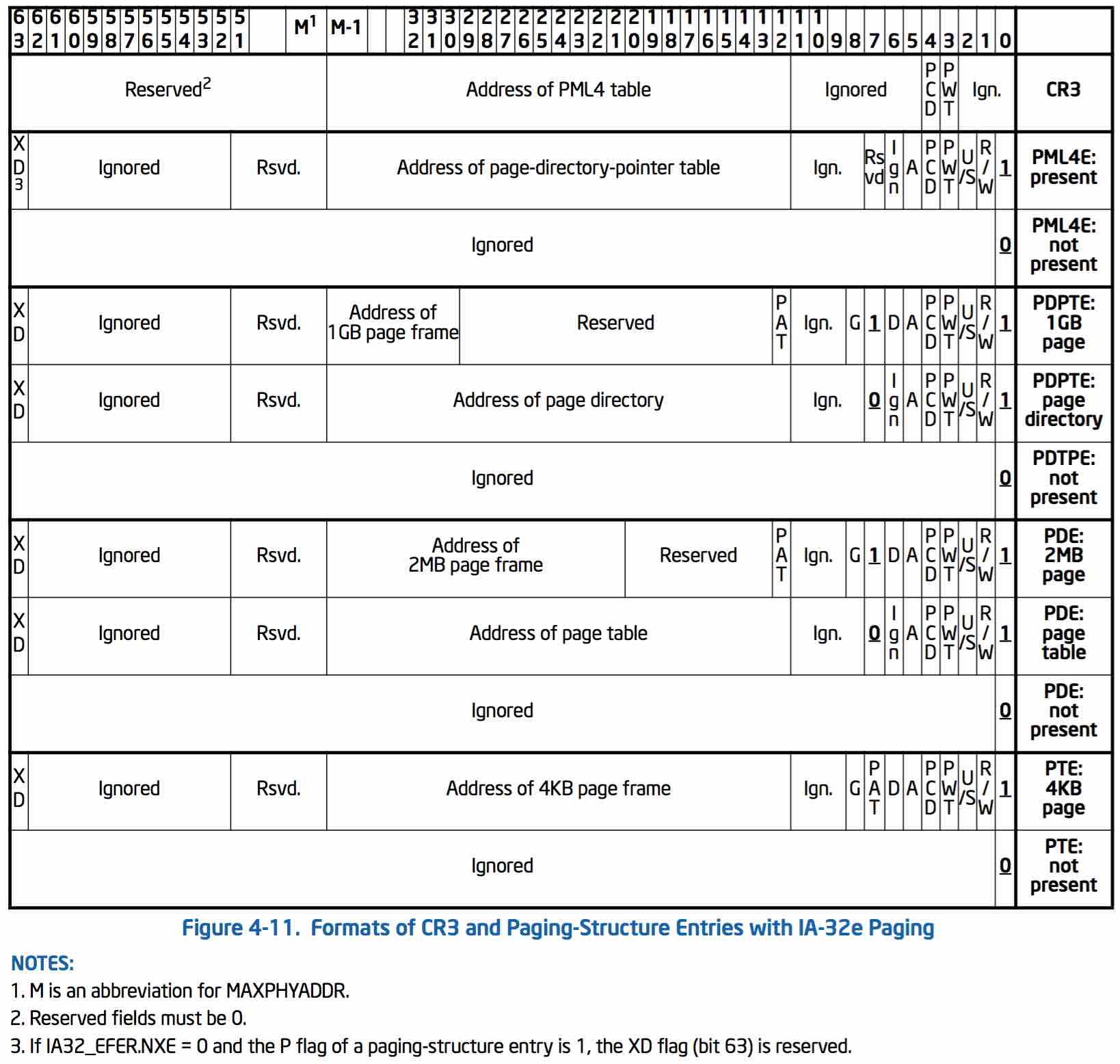
x86_64架构下Linux用了四级页表来表示一个映射关系,依次为PGD、PUD、PMD、PT。每级页表4K大小,内部元素大小为8字节,高位指向了下一级页表的物理地址,低位表示页表属性(是否存在、读写权限、是否脏等等)。顶层页表PGD的物理地址存放在CPU的CR3寄存器中,供MMU访问。48位线性地址也相应地分成了五段:前四段,每段长9位,用来索引对应页表的元素;最后一段长12位,用来在页面中索引物理地址。各级页表的详细内容参考下表:
3.页异常处理
一个进程初始运行时,对应的页表项大多都是空的。一旦MMU在地址转换过程中出现缺页或者读写权限问题时,MMU会触发页异常,打断CPU当前正在执行的程序,转而进行页异常处理(缺页会分配新页)。当页异常处理完毕后,CPU会重新执行引发缺页的指令,此时MMU便可正常完成地址转换。
下面,我们进一步深入分析整个页异常处理过程,关键流程如下图所示:
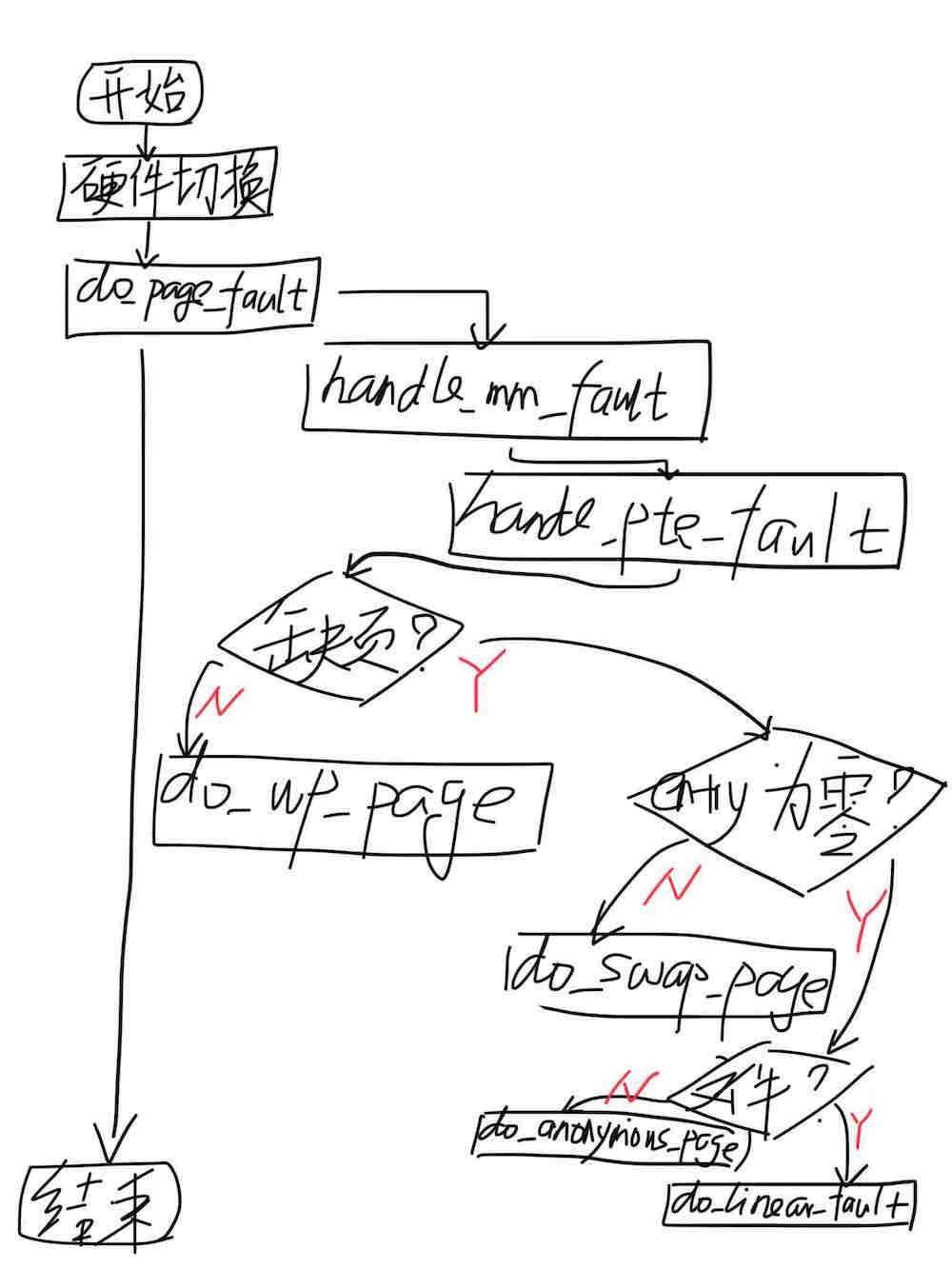
CPU收到页异常后,首先进行的是上下文切换的硬件过程,该过程主要完成栈的切换(进入内核栈)、关键寄存器的保存和执行函数的切换(转入页异常处理函数page_fault)。有关中断和异常处理的详细分析请参考中断分析。
CPU被页异常中断后最先执行的是一段汇编代码(page_fault位于linux/arch/x86/kernel/entry_64.S,感兴趣的同学可以自行分析),它完成了其他上下文寄存器的保存,并进入核心处理逻辑do_page_fault。
在理解MMU的工作原理之后,我想大家对缺页异常的核心处理逻辑应该很快能想明白,无非就是分配页、填充页内容、修改页表。然而,回顾一下前面线性地址章节描绘的地址空间分配图,我们会发现其中有代码、有数据、有堆和栈,不同类型的区段的对于页异常的处理逻辑是有区别的,例如代码段的页内容来自可执行文件,是只读类型的;数据段初始内容也来自可执行文件,但后续的修改不影响可执行执行文件;堆和栈的内容不来自任何文件,只在当前进程内部可见。因此,针对不同类型的内存区段需要有不同的处理方式。Linux内核以虚拟内存段(vma, virtual memory area)来表达不同程序区段,不同段可以具有不同的读写权限和属性;不在任何内存段的地址则认为是非法地址。有关内存段的数据结构如下:
linux/include/mm_types.h:
/*
* This struct defines a memory VMM memory area. There is one of these
* per VM-area/task. A VM area is any part of the process virtual memory
* space that has a special rule for the page-fault handlers (ie a shared
* library, the executable area etc).
*/
struct vm_area_struct {
/* The first cache line has the info for VMA tree walking. */
unsigned long vm_start; /* Our start address within vm_mm. */
unsigned long vm_end; /* The first byte after our end address within vm_mm. */
/* linked list of VM areas per task, sorted by address */
struct vm_area_struct *vm_next, *vm_prev;
struct rb_node vm_rb;
...
/* Second cache line starts here. */
struct mm_struct *vm_mm; /* The address space we belong to. */
pgprot_t vm_page_prot; /* Access permissions of this VMA. */
unsigned long vm_flags; /* Flags, see mm.h. */
...
/* Function pointers to deal with this struct. */
const struct vm_operations_struct *vm_ops;
/* Information about our backing store: */
unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE units, *not* PAGE_CACHE_SIZE */
struct file * vm_file; /* File we map to (can be NULL). */
void * vm_private_data; /* was vm_pte (shared mem) */
...
};
所有vma会以链表形式统一到mm_struct中,该结构每个进程拥有一个,被进程控制块使用,描述了每个进程的有效内存区段和地址映射关系:
linux/include/mm_types.h:
struct mm_struct {
struct vm_area_struct * mmap; /* list of VMAs */
struct rb_root mm_rb;
struct vm_area_struct * mmap_cache; /* last find_vma result */
#ifdef CONFIG_MMU
unsigned long (*get_unmapped_area) (struct file *filp,
unsigned long addr, unsigned long len,
unsigned long pgoff, unsigned long flags);
void (*unmap_area) (struct mm_struct *mm, unsigned long addr);
#endif
unsigned long mmap_base; /* base of mmap area */
unsigned long mmap_legacy_base; /* base of mmap area in bottom-up allocations */
unsigned long task_size; /* size of task vm space */
unsigned long cached_hole_size; /* if non-zero, the largest hole below free_area_cache */
unsigned long free_area_cache; /* first hole of size cached_hole_size or larger */
unsigned long highest_vm_end; /* highest vma end address */
pgd_t * pgd; /* 指向PGD表,owner进程运行时该值被加载到CR3寄存器中*/
atomic_t mm_users; /* How many users with user space? */
atomic_t mm_count; /* How many references to "struct mm_struct" (users count as 1) */
int map_count; /* number of VMAs */
spinlock_t page_table_lock; /* Protects page tables and some counters */
struct rw_semaphore mmap_sem;
struct list_head mmlist; /* List of maybe swapped mm's. These are globally strung
* together off init_mm.mmlist, and are protected
* by mmlist_lock
*/
...
}
我们回到do_page_fault函数,它通过读取CPU的CR2寄存器可以获知发生页异常的线性地址,并在当前进程对应的mm_struct中查找该线性地址对应的vma虚拟地址内存段,最后根据vma的属性来进一步处理页异常。当然,如果找不到线性地址对应的vma,内核就会认为发生了一次非法内存访问(让程序猿闻风丧胆的segfault由此产生)。代码片断分析如下:
linux/arch/x86/mm/fault.c:
/*
* This routine handles page faults. It determines the address,
* and the problem, and then passes it off to one of the appropriate
* routines.
*/
static void __kprobes
__do_page_fault(struct pt_regs *regs, unsigned long error_code)
{
struct vm_area_struct *vma;
struct task_struct *tsk;
unsigned long address;
struct mm_struct *mm;
int fault;
unsigned int flags = FAULT_FLAG_ALLOW_RETRY | FAULT_FLAG_KILLABLE;
tsk = current; /*获取当前进程*/
mm = tsk->mm; /*当前进程对应的mm_struct*/
/* Get the faulting address: */
address = read_cr2(); /*x86架构下,页异常发生时,CR2寄存器中会记录发生异常的线性地址*/
if (unlikely(fault_in_kernel_space(address))) {
/*通过异常地址范围,判断异常地址是否在内核态。
如果发生在内核态,通常是由于vmalloc导致的,这里会处理页表映射关系*/
...
return;
}
...
/*如果执行到这里,说明页异常地址处在用户态范围*/
/*如果代码段也在用户态,则打开中断,并记录标志;
如果代码段在内核态,则根据页异常发生前的IF标记值来决定是否打开中断*/
if (user_mode_vm(regs)) {
local_irq_enable();
error_code |= PF_USER;
flags |= FAULT_FLAG_USER;
} else {
if (regs->flags & X86_EFLAGS_IF)
local_irq_enable();
}
...
/*
* If we're in an interrupt, have no user context or are running
* in an atomic region then we must not take the fault:
*/
/*这里注意一点:页异常处理属于进程上下文,不是中断上下文,可睡眠*/
if (unlikely(in_atomic() || !mm)) {
bad_area_nosemaphore(regs, error_code, address);
return;
}
if (error_code & PF_WRITE)
flags |= FAULT_FLAG_WRITE;
/*
* When running in the kernel we expect faults to occur only to
* addresses in user space. All other faults represent errors in
* the kernel and should generate an OOPS. Unfortunately, in the
* case of an erroneous fault occurring in a code path which already
* holds mmap_sem we will deadlock attempting to validate the fault
* against the address space. Luckily the kernel only validly
* references user space from well defined areas of code, which are
* listed in the exceptions table.
* ...
*/
/*获取当前mm_struct的读信号量,避免后续处理过程中有其它流程修改mm_struct结构*/
if (unlikely(!down_read_trylock(&mm->mmap_sem))) {
if ((error_code & PF_USER) == 0 &&
!search_exception_tables(regs->ip)) {
bad_area_nosemaphore(regs, error_code, address);
return;
}
retry:
down_read(&mm->mmap_sem);
} else {
/*
* The above down_read_trylock() might have succeeded in
* which case we'll have missed the might_sleep() from
* down_read():
*/
might_sleep();
}
/*查找页异常地址对应的vma区段*/
vma = find_vma(mm, address);
if (unlikely(!vma)) {
bad_area(regs, error_code, address);
return;
}
/*如果页异常地址在合理的vma段地址范围内,则进行后续的异常处理*/
if (likely(vma->vm_start <= address))
goto good_area;
if (unlikely(!(vma->vm_flags & VM_GROWSDOWN))) {
/*如果页异常地址小于vma起始地址,但vma又不是往低地址方向增长(栈是往低地址方向增长的),则出现错误*/
bad_area(regs, error_code, address);
return;
}
...
/*往低地址方向增长栈*/
if (unlikely(expand_stack(vma, address))) {
bad_area(regs, error_code, address);
return;
}
/*
* Ok, we have a good vm_area for this memory access, so
* we can handle it..
*/
/*如果执行到这里,后续便开始针对vma的属性进行不同的页异常处理*/
good_area:
if (unlikely(access_error(error_code, vma))) {
bad_area_access_error(regs, error_code, address);
return;
}
/*
* If for any reason at all we couldn't handle the fault,
* make sure we exit gracefully rather than endlessly redo
* the fault:
*/
fault = handle_mm_fault(mm, vma, address, flags);
...
}
/*下面补充一些关于页异常错误码的内容,通常在发生段错误时我们在系统日志中可以看到错误码,
通过错误码我们大致可以得知异常发生的原因*/
/*
* Page fault error code bits:
*
* bit 0 == 0: no page found 1: protection fault
* bit 1 == 0: read access 1: write access
* bit 2 == 0: kernel-mode access 1: user-mode access
* bit 3 == 1: use of reserved bit detected
* bit 4 == 1: fault was an instruction fetch
*/
enum x86_pf_error_code {
PF_PROT = 1 << 0,
PF_WRITE = 1 << 1,
PF_USER = 1 << 2,
PF_RSVD = 1 << 3,
PF_INSTR = 1 << 4,
};
handle_mm_fault函数基于当前进程的mm_struct、异常地址所在vma和异常处理控制标志flags进行进一步异常处理。我们知道,页表共有四级,这里依次对各级页表进行处理:PGD是在进程创建的时候就分配好的,不需要动态分配,其值保存在mm_struct的pgd域中;从PUD到PT,如果页表不存在会动态分配页并使页表指向新分配的页。页表处理完成后,进入handle_pte_fault处理最后的物理页。handle_mm_fault代码注解如下(这里暂不考虑大页等复杂特性):
linux/mm/memory.c:
/*
* By the time we get here, we already hold the mm semaphore
*/
static int __handle_mm_fault(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, unsigned int flags)
{
pgd_t *pgd;
pud_t *pud;
pmd_t *pmd;
pte_t *pte;
...
retry:
pgd = pgd_offset(mm, address); /*直接获取当前进程中页异常线性地址在PGD表中对应的项,无须分配*/
pud = pud_alloc(mm, pgd, address); /*获取PUD表中对应的项,如果PUD表不存在则动态分配*/
if (!pud)
return VM_FAULT_OOM;
pmd = pmd_alloc(mm, pud, address); /*获取PMD表中对应的项,如果PMD不存在则动态分配*/
if (!pmd)
return VM_FAULT_OOM;
...
if (unlikely(pmd_none(*pmd)) &&
unlikely(__pte_alloc(mm, vma, pmd, address))) /*动态分配PTE*/
return VM_FAULT_OOM;
...
pte = pte_offset_map(pmd, address);
/*各级页表分配完毕后,真正开始处理页异常*/
return handle_pte_fault(mm, vma, address, pte, pmd, flags);
}
题外话,页表操作的同步。通常情况下,一个确定的映射关系mm_struct只被一个进程引用,同一进程在确定时刻只会运行在一个核上,因此该进程的页异常处理也只在一个核上发生,此时不存在对进程页表做并发操作的可能。然而,如果一个进程有多个线程,那么这些线程将引用相同的mm_struct(代码段、数据段、堆空间完全相同,栈空间各不相同),此时对mm_struct所涉及的各级页表操作时就需要考虑同步问题。
一种简单的方法是在开始页表操作前,对mm_struct先上一把大锁,待各级页表均操作完毕后再解锁。但存在的问题是页表操作过程中会涉及页分配,这是一个极其复杂的过程,可能还会睡眠,这样一来有可能出现成功加到锁的线程进入睡眠态后导致其他线程缺页却加不到锁的情况。即便不同线程访问的是不同内存段,但是却有可能出现因为一个线程的页异常处理不及时导致所有线程无法正常处理页异常的情况。
linux内核针对此种问题采用了最小化加锁范围的方法。每次操作页表前,如果页表项不存在则先分配页,然后加mm_struct锁。加锁成功后,如果发现页表项已经被赋值,说明有其他CPU先于当前CPU完成了页表分配,则释放先前分配页并解锁;如果未被赋值,则将分配页赋值给页表项,最后解锁。这种方法虽然会导致一些多余的页分配和释放动作,但加锁区间和持锁时间大大缩短,系统整体并发性大大提升。此外,对于最后一级PT页表的操作比前几级页表复杂性要高得多,因此内核对PT页表使用了一把独立的锁,进一步提升系统并行效率。代码注解如下:
int __pud_alloc(struct mm_struct *mm, pgd_t *pgd, unsigned long address)
{
pud_t *new = pud_alloc_one(mm, address); /*先偿试分配一页,该过程执行时间可能会比较长*/
if (!new)
return -ENOMEM;
smp_wmb(); /* See comment in __pte_alloc */
/*加锁判断原有页表项是否改变,如果发生改变说明有其它流程已成功分配页表,这里就释放之间分配的页*/
spin_lock(&mm->page_table_lock);
if (pgd_present(*pgd)) /* Another has populated it */
pud_free(mm, new);
else
pgd_populate(mm, pgd, new);
spin_unlock(&mm->page_table_lock);
return 0;
}
我们再回到页异常处理主逻辑,接下来handle_pte_fault函数根据PT页表中异常地址对应的页表项进行不同处理:如果页表项PRESENT位未被置位,代表物理页不存在,需要进行缺页处理;否则,代表访问权限不够,需要调用do_wp_page进行写保护处理。在缺页的情况下,如果页表项不为零,说明前期把物理页交换到磁盘上了,而页表项纪录了交换页所在的磁盘位置信息,那么此时需要通过do_swap_page将交换页取回内存(内存交换将单独起一篇博文分析);页表项为零则根据vma是否有文件对应进行不同处理,文件映射由do_linear_fault处理,匿名映射由do_anonymous_page处理。handle_pte_fault代码注解如下:
linux/mm/memory.c:
int handle_pte_fault(struct mm_struct *mm,
struct vm_area_struct *vma, unsigned long address,
pte_t *pte, pmd_t *pmd, unsigned int flags)
{
pte_t entry;
spinlock_t *ptl;
entry = *pte;
if (!pte_present(entry)) { /*判断页是否不存在*/
if (pte_none(entry)) { /*如果不仅不存在,而且页表项内容为零*/
if (vma->vm_ops) /*文件映射*/
return do_linear_fault(mm, vma, address, pte, pmd, flags, entry);
return do_anonymous_page(mm, vma, address, pte, pmd, flags); /*匿名映射*/
}
...
/*页不存在,但是非零,表示指向一个交换页,则执行换入操作*/
return do_swap_page(mm, vma, address, pte, pmd, flags, entry);
}
...
/*处理防问权限异常,如写保护异常*/
ptl = pte_lockptr(mm, pmd);
spin_lock(ptl);
if (unlikely(!pte_same(*pte, entry)))
goto unlock;
if (flags & FAULT_FLAG_WRITE) {
if (!pte_write(entry))
return do_wp_page(mm, vma, address, pte, pmd, ptl, entry);
entry = pte_mkdirty(entry);
}
...
}
do_linear_fault函数处理线性文件映射内存段的缺页问题。对于读缺页,通过查找文件缓存页后直接采用缓存页作为映射页;对于写缺页,先查找文件缓存页,如果为共享内存段则直接采用缓存页映射,如果为私有内存段则分配新页、拷贝缓存页内容后再映射新页。代码注解如下:
linux/mm/memory.c:
static int do_linear_fault(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, pte_t *page_table, pmd_t *pmd,
unsigned int flags, pte_t orig_pte)
{
pgoff_t pgoff = (((address & PAGE_MASK)
- vma->vm_start) >> PAGE_SHIFT) + vma->vm_pgoff; /*计算异常地址对应内容在文件中的偏移*/
return __do_fault(mm, vma, address, pmd, pgoff, flags, orig_pte);
}
static int __do_fault(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, pmd_t *pmd,
pgoff_t pgoff, unsigned int flags, pte_t orig_pte)
{
pte_t *page_table;
spinlock_t *ptl;
struct page *page;
struct page *cow_page;
pte_t entry;
int anon = 0;
struct page *dirty_page = NULL;
struct vm_fault vmf;
int ret;
/*对于写操作,如果页异常地址所在vma段的属性是私有的,即没有设置VM_SHARED标记,
则需要分配一个匿名页并复制文件中的内容*/
if ((flags & FAULT_FLAG_WRITE) && !(vma->vm_flags & VM_SHARED)) {
if (unlikely(anon_vma_prepare(vma)))
return VM_FAULT_OOM;
cow_page = alloc_page_vma(GFP_HIGHUSER_MOVABLE, vma, address);
if (!cow_page)
return VM_FAULT_OOM;
...
} else
cow_page = NULL;
vmf.virtual_address = (void __user *)(address & PAGE_MASK);
vmf.pgoff = pgoff;
vmf.flags = flags;
vmf.page = NULL;
/*通过文件系统中的fault操作,在vmf.page中返回页异常地址对应文件内容的缓存页*/
ret = vma->vm_ops->fault(vma, &vmf);
...
page = vmf.page;
if (flags & FAULT_FLAG_WRITE) {
if (!(vma->vm_flags & VM_SHARED)) {
page = cow_page;
anon = 1;
copy_user_highpage(page, vmf.page, address, vma); /*复制缓存页中的内容到匿名页*/
__SetPageUptodate(page);
} else {
...
}
}
page_table = pte_offset_map_lock(mm, pmd, address, &ptl);
if (likely(pte_same(*page_table, orig_pte))) { /*通常都会进入该分支,是一种高效的页表访问方式*/
entry = mk_pte(page, vma->vm_page_prot); /*将页地址和基本属性填入页表项*/
if (flags & FAULT_FLAG_WRITE)
entry = maybe_mkwrite(pte_mkdirty(entry), vma); /*设置页表项写权限*/
if (anon) { /*如果是匿名页,则添加反向匿名映射*/
inc_mm_counter_fast(mm, MM_ANONPAGES);
page_add_new_anon_rmap(page, vma, address);
} else { /*如果是文件映射,则添加反向文件映射*/
inc_mm_counter_fast(mm, MM_FILEPAGES);
page_add_file_rmap(page);
if (flags & FAULT_FLAG_WRITE) {
dirty_page = page;
get_page(dirty_page);
}
}
set_pte_at(mm, address, page_table, entry); /*最终修改页表项内容*/
...
} else {
...
}
pte_unmap_unlock(page_table, ptl);
...
}
do_anonymous_page函数处理匿名映射内存段的缺页问题。由于匿名映射没有对应文件,这里直接分配新页进行映射。代码注解如下:
static int do_anonymous_page(struct mm_struct *mm, struct vm_area_struct *vma,
unsigned long address, pte_t *page_table, pmd_t *pmd,
unsigned int flags)
{
struct page *page;
spinlock_t *ptl;
pte_t entry;
...
/* Allocate our own private page. */
if (unlikely(anon_vma_prepare(vma)))
goto oom;
page = alloc_zeroed_user_highpage_movable(vma, address);
if (!page)
goto oom;
/*
* The memory barrier inside __SetPageUptodate makes sure that
* preceeding stores to the page contents become visible before
* the set_pte_at() write.
*/
__SetPageUptodate(page);
entry = mk_pte(page, vma->vm_page_prot);
if (vma->vm_flags & VM_WRITE)
entry = pte_mkwrite(pte_mkdirty(entry));
page_table = pte_offset_map_lock(mm, pmd, address, &ptl);
...
inc_mm_counter_fast(mm, MM_ANONPAGES);
page_add_new_anon_rmap(page, vma, address);
setpte:
set_pte_at(mm, address, page_table, entry);
...
unlock:
pte_unmap_unlock(page_table, ptl);
return 0;
...
}
do_wp_page函数处理写保护,即针对没有写权限的映射页触发了写请求。这里的处理思路和匿名页处理有些类似,也是分配新页后拷贝原有页的内容,之后解除原有页的映射之后再映射新页。
至此,MMU和CPU的内存地址映射功能已经整体分析完毕。CPU在页异常过程中多次涉及内存页分配,而内存分配又牵扯到内存回收和交换,这些都内存管理中不可缺少的部分,后续将对这些部分进行深入分析。
转载请注明:吴斌的博客 » 【计算子系统】内存管理之一:地址映射