
本节将讨论内存分配,计算子系统相关内容目录点此进入。
什么是内存分配?为什么需要它?有何技术难点?
前文分析页异常处理时,我们看到内核会为应用程序分配内存页,而应用程序本身不直接申请内存页(只会通过malloc在堆中动态申请内存)。此外,内核在处理系统调用或中断时,也有可能需要动态申请页。Linux内核实现内存页申请的接口是alloc_pages(gfp_mask, order):其中,gfp_mask代表申请内存的方式(隐含内存用途),控制内存分配的行为;order代表需要的连续内存页个数的阶;接口返回的是连续内存首页对应的struct page指针(还记得地址映射中介绍的virtual memory map么?)。
通过动态分配内存页,可以提升系统对内存资源的利用率。然而,在内存不断的申请和释放过程中,可以想象的一个问题就是碎片化,即剩余内存分布在各段非连续空间内,使得较大连续内存的申请无法得到满足。因此内存分配算法的主要目标就是避免碎片化。
有的同学可能会问,为什么一定需要连续的物理内存呢?页表机制可以把非连续的物理页映射到连续的虚拟地址空间,这样应用程序看到的不就是连续内存了吗?的确,对于应用程序来说,对连续内存页的需求不是很强烈,但是对于某些外设(例如DMA设备)来说,它们只能看到物理页,而不存在页表转换过程,此时内核只能分配连续物理页来满足设备的内存访问需求。所以连续的物理内存在内核看来是一种稀缺资源,内存分配时需要尽可能保证剩余内存的连续性。下面我们就来看看Linux内核中内存的分配算法。
如何实现?- 优化型伙伴算法
说到内存分配算法,不得不提一提耳熟能详、在各类教科书中不断被说明的伙伴算法(buddy algorithm)。连续内存被划分成各阶大小(1,2,4,8,…)的内存段,阶数相同且低地址段起始地址按阶对齐的相邻段被称为伙伴,如下图所示:
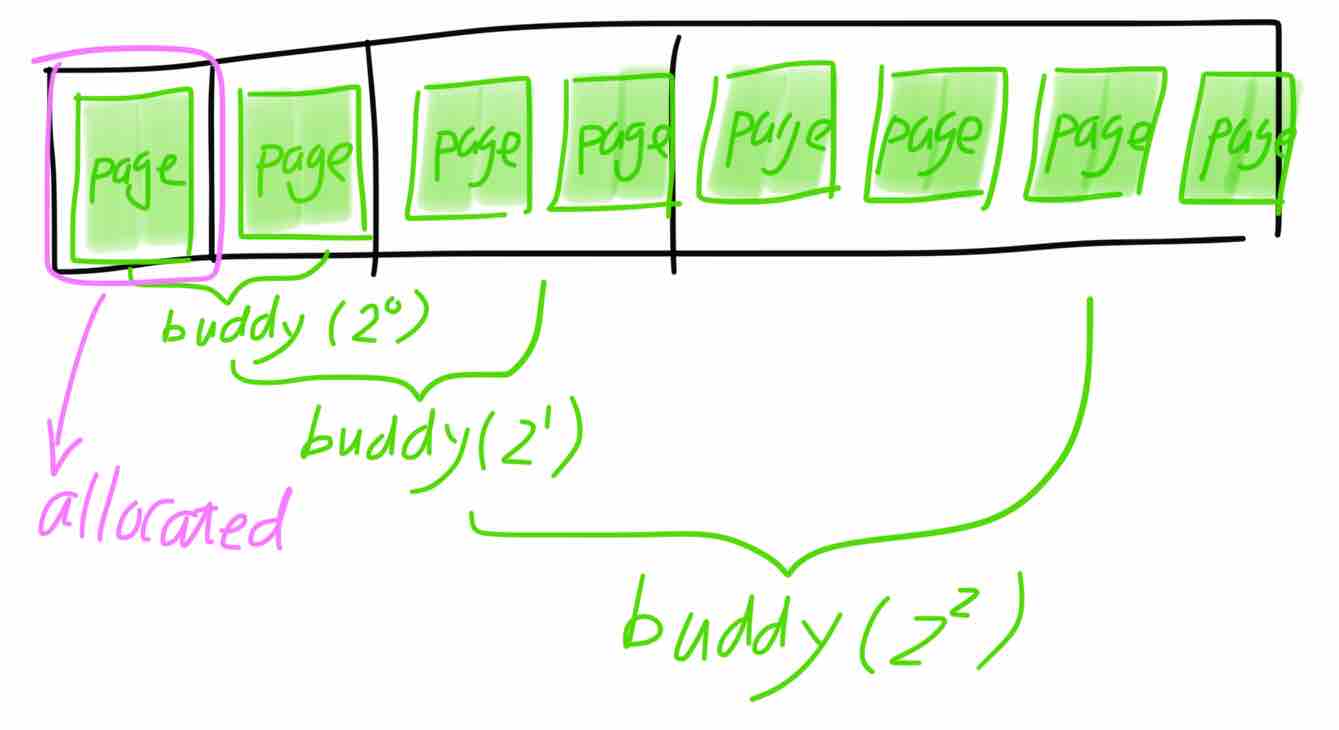
图中所示为连续八页内存中被分配出去一页时的状态:剩余内存被分为三段,分别为一个页、两个页和四个页。
伙伴算法的原理为:初始时,所有连续内存按最大阶(Linux中为10,代表最大连续页为1024页)划分成段。内存分配时按阶数从小到大的顺序寻找最先能满足当前分配大小的连续段,如果找到的段的阶大于分配需要的阶,则将找到的段拆分成低阶段,例如上图表示将从一个3阶内存段中分配一个0阶内存段(即一页)的情况。内存释放时,如果发现被释放页的伙伴页段均空闲,则将两个伙伴合并从一个大的连续段并继续尝试合并新段和它的伙伴,直到无法合并为止。因此只要相邻伙伴均被释放,内存总是能被合并成更大的页段,这就是伙伴算法名称的由来。
伙伴算法真的完美吗?它在分配内存页时确实在努力保证剩余内存的连续,即在小段连续内存能满足当前分配的情况下绝对不会去动用大段连续内存,这就防止了因分配不当产生碎片。然而,它却无法避免因连续分配和释放而产生的碎片,因为只有当相邻两个伙伴均空闲时才能进行合并,这意味着一个伙伴的占用将阻止内存合并的发生。
因伙伴页被长期占用而导致的碎片问题的确比分配产生的碎片要难处理得多。这不由让人联想到磁盘的“碎片整理”功能,也就是通过移动正在使用的空间来保证剩余空间的连续。那么我们是否可以将类似思路应用到内存管理中呢?
通过观察我们可以发现使用中的内存页也具有一定的移动性:对于分配给应用程序使用的页是可以移动的(movable),因为通过页表的重映射可以在应用不感知的前提下实现页替换;对于分配给内核自身使用的页是不可移动的(unmovable),因为内核以直接映射的方式访问该页;对于未被映射给应用的缓存页是可回收的(reclaimable),因为回刷缓存后缓存页可直接释放。如果我们将不可移动或回收的页限定在一定的范围内,就可以保证剩余范围内的页是可移动的,那么我们就可以在剩余范围内通过移动内存页来实现“碎片整理”。Linux内核就是基于上述思路,将伙伴算法中的各阶空闲内存细分成不可移动、可回收和可移动三大类,分配时通过gfp_mask标志来控制从哪类内存中分配空间。对于可移动内存页,内核在内存不足时会进行内存压缩(compact)来尝试形成更大的连续内存。上述算法即是优化型伙伴算法。
下面我们结合代码来深入理解优化型伙伴算法。
linux/mm/page_alloc.c:
/*
* This is the 'heart' of the zoned buddy allocator.
*/
struct page *
__alloc_pages_nodemask(gfp_t gfp_mask, unsigned int order,
struct zonelist *zonelist, nodemask_t *nodemask)
{
/*在开始分析代码之前,先要理解NUMA这个概念:Non Uniform Memory Access,即非统一内存访问。
我们前文举例的i440fx并不属于NUMA架构,NUMA架构通常会有多个计算节点,每个节点都有独立的内
存,且每个节点在访问本地内存时的性能优于远端节点。linux内核通过ACPI中的SRAT表获知详细的
NUMA信息。当然,我们可以将i440fx简单理解成只有一个节点的NUMA系统。*/
/*此外,内核会将整体物理内存空间划分成不同的区段(zone):DMA段-16M地址空间以下;DMA32段-
4G地址空间以下;Normal段-4G以上内存。因此每个NUMA节点可能包含多个zone。linux内核针对
zone进行内存分配管理(伙伴算法)。*/
/*参数zonelist是根据gfp_mask计算得出的,以GFP_KERNEL为例,zonelist指向的通常就是当前进
程所在NUMA节点包含的所有zone(内存分配策略为node first)。nodemask表示内存分配时需要过滤
哪些节点,NULL表示不过滤任何节点。*/
enum zone_type high_zoneidx = gfp_zone(gfp_mask); /*根据gfp_mask计算可分配的最
大zone(Normal > DMA32 > DMA),zone越小表示内存
资源越稀缺。以GFP_KERNEL为例,这里计算可得normal*/
struct zone *preferred_zone;
struct page *page = NULL;
int migratetype = allocflags_to_migratetype(gfp_mask); /*根据GFP中的__GFP_MOVABLE
和__GFP_RECLAIMABLE标志计算待分配页的迁移类型,以
GFP_KERNEL为例,这里计算得出MIGRAGE_UNMOVABLE*/
...
/*先进行快速内存分配策略,大部分分配动作将在该函数中成功返回。如果空闲内存不足,快速分配会
偿试内存回收*/
page = get_page_from_freelist(gfp_mask|__GFP_HARDWALL, nodemask, order,
zonelist, high_zoneidx, alloc_flags, preferred_zone, migratetype);
if (unlikely(!page)) {
...
/*如果快速分配失败,再进行慢速分配*/
page = __alloc_pages_slowpath(gfp_mask, order,
zonelist, high_zoneidx, nodemask, preferred_zone, migratetype);
}
...
return page;
}
/*下面我们补充一些内存分配标记相关的内容:*/
linux/include/linux/gfp.h:
/*
* Action modifiers - doesn't change the zoning
*
* __GFP_REPEAT: Try hard to allocate the memory, but the allocation attempt
* _might_ fail. This depends upon the particular VM implementation.
*
* __GFP_NOFAIL: The VM implementation _must_ retry infinitely: the caller
* cannot handle allocation failures. This modifier is deprecated and no new
* users should be added.
*
* __GFP_NORETRY: The VM implementation must not retry indefinitely.
*
* __GFP_MOVABLE: Flag that this page will be movable by the page migration
* mechanism or reclaimed
*/
#define __GFP_WAIT ((__force gfp_t)___GFP_WAIT) /* Can wait and reschedule? */
#define __GFP_HIGH ((__force gfp_t)___GFP_HIGH) /* Should access emergency pools? */
#define __GFP_IO ((__force gfp_t)___GFP_IO) /* Can start physical IO? */
#define __GFP_FS ((__force gfp_t)___GFP_FS) /* Can call down to low-level FS? */
#define __GFP_COLD ((__force gfp_t)___GFP_COLD) /* Cache-cold page required */
#define __GFP_NOWARN ((__force gfp_t)___GFP_NOWARN) /* Suppress page allocation failure warning */
#define __GFP_REPEAT ((__force gfp_t)___GFP_REPEAT) /* See above */
#define __GFP_NOFAIL ((__force gfp_t)___GFP_NOFAIL) /* See above */
#define __GFP_NORETRY ((__force gfp_t)___GFP_NORETRY) /* See above */
#define __GFP_MEMALLOC ((__force gfp_t)___GFP_MEMALLOC)/* Allow access to emergency reserves */
#define __GFP_COMP ((__force gfp_t)___GFP_COMP) /* Add compound page metadata */
#define __GFP_ZERO ((__force gfp_t)___GFP_ZERO) /* Return zeroed page on success */
#define __GFP_NOMEMALLOC ((__force gfp_t)___GFP_NOMEMALLOC) /* Don't use emergency reserves.
* This takes precedence over the
* __GFP_MEMALLOC flag if both are
* set
*/
#define __GFP_HARDWALL ((__force gfp_t)___GFP_HARDWALL) /* Enforce hardwall cpuset memory allocs */
#define __GFP_THISNODE ((__force gfp_t)___GFP_THISNODE)/* No fallback, no policies */
#define __GFP_RECLAIMABLE ((__force gfp_t)___GFP_RECLAIMABLE) /* Page is reclaimable */
#define __GFP_NOTRACK ((__force gfp_t)___GFP_NOTRACK) /* Don't track with kmemcheck */
#define __GFP_NO_KSWAPD ((__force gfp_t)___GFP_NO_KSWAPD)
#define __GFP_OTHER_NODE ((__force gfp_t)___GFP_OTHER_NODE) /* On behalf of other node */
#define __GFP_KMEMCG ((__force gfp_t)___GFP_KMEMCG) /* Allocation comes from a memcg-accounted resource */
#define __GFP_WRITE ((__force gfp_t)___GFP_WRITE) /* Allocator intends to dirty page */
/*
* This may seem redundant, but it's a way of annotating false positives vs.
* allocations that simply cannot be supported (e.g. page tables).
*/
#define __GFP_NOTRACK_FALSE_POSITIVE (__GFP_NOTRACK)
#define __GFP_BITS_SHIFT 25 /* Room for N __GFP_FOO bits */
#define __GFP_BITS_MASK ((__force gfp_t)((1 << __GFP_BITS_SHIFT) - 1))
/* This equals 0, but use constants in case they ever change */
#define GFP_NOWAIT (GFP_ATOMIC & ~__GFP_HIGH)
/* GFP_ATOMIC means both !wait (__GFP_WAIT not set) and use emergency pool */
#define GFP_ATOMIC (__GFP_HIGH)
#define GFP_NOIO (__GFP_WAIT)
#define GFP_NOFS (__GFP_WAIT | __GFP_IO)
#define GFP_KERNEL (__GFP_WAIT | __GFP_IO | __GFP_FS)
#define GFP_TEMPORARY (__GFP_WAIT | __GFP_IO | __GFP_FS | \
__GFP_RECLAIMABLE)
#define GFP_USER (__GFP_WAIT | __GFP_IO | __GFP_FS | __GFP_HARDWALL)
#define GFP_HIGHUSER (__GFP_WAIT | __GFP_IO | __GFP_FS | __GFP_HARDWALL | \
__GFP_HIGHMEM)
#define GFP_HIGHUSER_MOVABLE (__GFP_WAIT | __GFP_IO | __GFP_FS | \
__GFP_HARDWALL | __GFP_HIGHMEM | \
__GFP_MOVABLE)
#define GFP_IOFS (__GFP_IO | __GFP_FS)
#define GFP_TRANSHUGE (GFP_HIGHUSER_MOVABLE | __GFP_COMP | \
__GFP_NOMEMALLOC | __GFP_NORETRY | __GFP_NOWARN | \
__GFP_NO_KSWAPD)
内存分配有一个快速分配流程和一个慢速分配流程,采用先快后慢的思路。快速分配根据zone内空闲内存量决定是否使用快速内存回收,如果空闲量足够的话,则直接采用优化型伙伴算法进行分配,否则先进行快速回收再尝试分配。快速分配一旦失败就会使用慢速分配的方式唤醒内存交换进程(kswapd)或触发内存压缩继续尝试分配。下面我们再深入看一下快速分配流程get_page_from_freelist:
linux/mm/page_alloc.c:
/*
* get_page_from_freelist goes through the zonelist trying to allocate
* a page.
*/
static struct page *
get_page_from_freelist(gfp_t gfp_mask, nodemask_t *nodemask, unsigned int order,
struct zonelist *zonelist, int high_zoneidx, int alloc_flags,
struct zone *preferred_zone, int migratetype)
{
struct zoneref *z;
struct page *page = NULL;
int classzone_idx;
struct zone *zone;
classzone_idx = zone_idx(preferred_zone);
zonelist_scan:
/*
* Scan zonelist, looking for a zone with enough free.
* See also cpuset_zone_allowed() comment in kernel/cpuset.c.
*/
/*下面的循环体开始遍历zonelist中的每个zone,最大为high_zoneidx,并过滤nodemask*/
for_each_zone_zonelist_nodemask(zone, z, zonelist, high_zoneidx, nodemask) {
...
if (!(alloc_flags & ALLOC_NO_WATERMARKS)) {
unsigned long mark;
int ret;
/*内存管理初始化时,分为每个zone设定high、low、min三档水位线:空闲内存量大于high表示
余量充足;空闲量小于high大于low表示有一定的内存压力,余量尚可;空闲量小于low大于min
表示内存压力较大,余量不足;空闲量小于min,表示内存压力非常大,需要动用紧急内存*/
/*快速分配时alloc_flags考量的是low水位线,只要当前zone的空闲内存量不低于low水位线,
都会偿试通过伙伴算法进行分配,否则就进行内存回收*/
mark = zone->watermark[alloc_flags & ALLOC_WMARK_MASK];
if (zone_watermark_ok(zone, order, mark, classzone_idx, alloc_flags))
goto try_this_zone;
...
ret = zone_reclaim(zone, gfp_mask, order); /*进行内存回收*/
switch (ret) {
case ZONE_RECLAIM_NOSCAN:
/* did not scan */
continue;
case ZONE_RECLAIM_FULL:
/* scanned but unreclaimable */
continue;
default:
/* did we reclaim enough */
/*回收部分内存后,如果水位线满足要求则偿试进行分配*/
if (zone_watermark_ok(zone, order, mark, classzone_idx, alloc_flags))
goto try_this_zone;
...
continue;
}
}
try_this_zone:
/*正式进行内存分配*/
page = buffered_rmqueue(preferred_zone, zone, order, gfp_mask, migratetype);
if (page)
break;
this_zone_full:
...
}
...
return page;
}
static inline
struct page *buffered_rmqueue(struct zone *preferred_zone,
struct zone *zone, int order, gfp_t gfp_flags, int migratetype)
{
unsigned long flags;
struct page *page;
again:
if (likely(order == 0)) {
/*对于单页内存的分配,内核为cpu预留了一部分缓存空间;分配和释放进首先从缓存中进行。
这样可以提升单页内存分配的效率,具体代码大家可以自行展开分析*/
...
} else {
spin_lock_irqsave(&zone->lock, flags);
/*偿试从当前zone中根据migratetype类型进行内存页分配,内部会调用__rmqueue_smallest*/
page = __rmqueue(zone, order, migratetype);
spin_unlock(&zone->lock);
...
}
...
return page;
...
}
/*__rmqueue_smallest就是伙伴算法最核心的代码实现,逻辑比较清楚,大家可以仔细阅读*/
static inline
struct page *__rmqueue_smallest(struct zone *zone, unsigned int order, int migratetype)
{
unsigned int current_order;
struct free_area * area;
struct page *page;
/*数据结构上,每个zone都有一个free_area数组,下标代表伙伴阶数,最大为10(MAX_ORDER为11)。
在优化型伙伴算法中,freea_area每个元素再次按迁移性分为不可移动、可移动、可回收三个部分*/
/* Find a page of the appropriate size in the preferred list */
for (current_order = order; current_order < MAX_ORDER; ++current_order) { /*阶数从小到大*/
area = &(zone->free_area[current_order]);
if (list_empty(&area->free_list[migratetype])) /*判断是否符合分配要求*/
continue;
page = list_entry(area->free_list[migratetype].next, struct page, lru);
list_del(&page->lru); /*将符合要求的连续页从伙伴系统中移除*/
rmv_page_order(page);
area->nr_free--;
expand(zone, page, order, current_order, area, migratetype); /*将打散的空闲页添加到低阶链表中*/
return page;
}
return NULL; /*如果找不到符合要求的空闲页,则返回空*/
}
至此,内存分配中核心的伙伴算法分析完毕,后续博文我们将沿着内存回收线索深入往下分析。
转载请注明:吴斌的博客 » 【计算子系统】内存管理之二:内存分配