
定义(what)
CUDA(Compute Unified Device Architecture),中文叫统一计算设备架构,它是NVIDIA公司基于自身异构计算设备(GPU)提出的一种统一串行计算(CPU完成)和并行计算(GPU完成)的可编程异构融合计算系统。GPU相比CPU而言,面对SIMD并行计算模式有成百上千倍的计算性能提升,且有着更低的功耗优势。因此GUDA也一种是执行串并行混合复杂任务的理想计算系统。
串行计算
对于一般性计算任务,总是可以分解成小的计算片段依次执行,这就是通常说的串行计算,如下图所示:

并行计算
对于复杂计算任务,并不是所有计算片段都有严格的数据依赖并需要按顺序执行,这里的数据依赖是指后面的计算片段的计算输入依赖前面的计算片段的输出。因此复杂计算中总是可以分解为几个大的串行计算区间,但是在某些区间内部存在可以并行执行的部分,如下图所示:
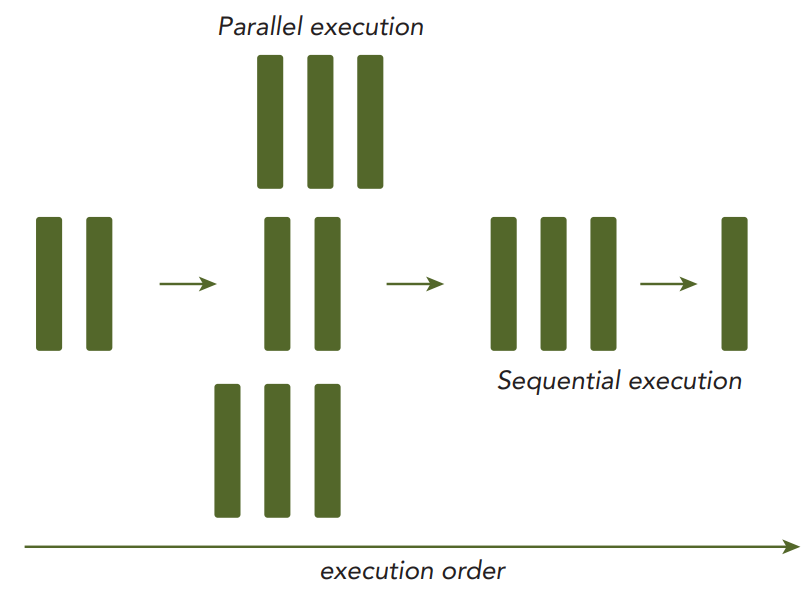
并行计算又可以分为任务并行和数据并行两种类型:任务并行是指多个无关任务可以在多个计算核上同时执行;而数据并行是指将大块数据的不同部分分散到不同的计算核上进行并行计算,以提升大块数据的计算性能。CUDA架构适合解决数据并行类问题。
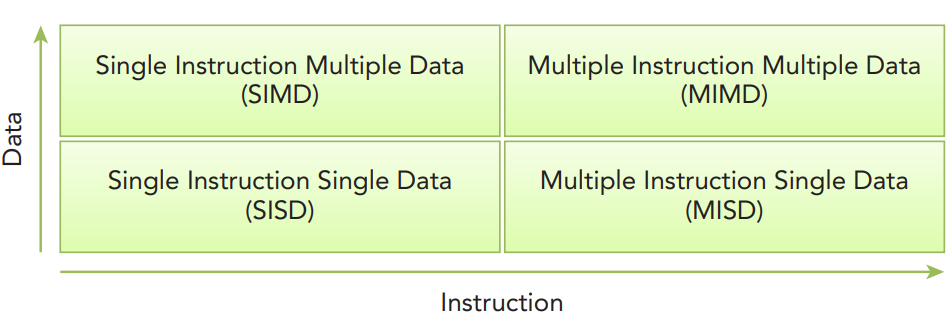
费林计算架构分类
无论串行计算还是并行计算,都需要相应的硬件计算架构来实现,而根据计算任务的指令和数据在多个计算核的流动和分散方式,计算架构可以分为:单指令多数据(SIMD)、多指令多数据(MIMD)、单指令单数据(SISD)、多指令单数据(MISD)四种模式。CUDA融合了SIMD、MIMD、多线程、指令级并行,因此也被称为SIMT架构,即单指令多线程架构。
串行计算与并行计算融合统一
CPU适合执行带有复杂控制逻辑的串行计算任务,GPU适合执行控制逻辑简单但数据并行度较高的并行计算任务。如果能对复杂任务在GPU和GPU间进行合理执行分配,任务执行将获得最佳性能和功耗优势:

价值(why)
CUDA对于线性代数运算(如矩阵、向量等)有数量级的性能提升,可应用于HPC(High Performance Computing)或AI类任务,如计算生物学和化学、流体力学模拟、CT 图像再现、地震分析以及深度学习模型训练与推理等等。
实现原理(how)
从硬件视角,一个最小CUDA系统整体上可分为CPU、GPU和互联总线(如PCIE)。CPU通常被称为主机侧(Host),GPU通常被称为设备侧(Device)。CPU内有较大电路面积用于实现控制逻辑(Control)和缓存加速(Cache),而计算单元(ALU)相对较少,因此适合执行控制逻辑复杂的任务;GPU内控制逻辑和缓存实现简单,但是确含有大量计算单元,因此适合执行控制逻辑简单而数据并行量较大的任务。
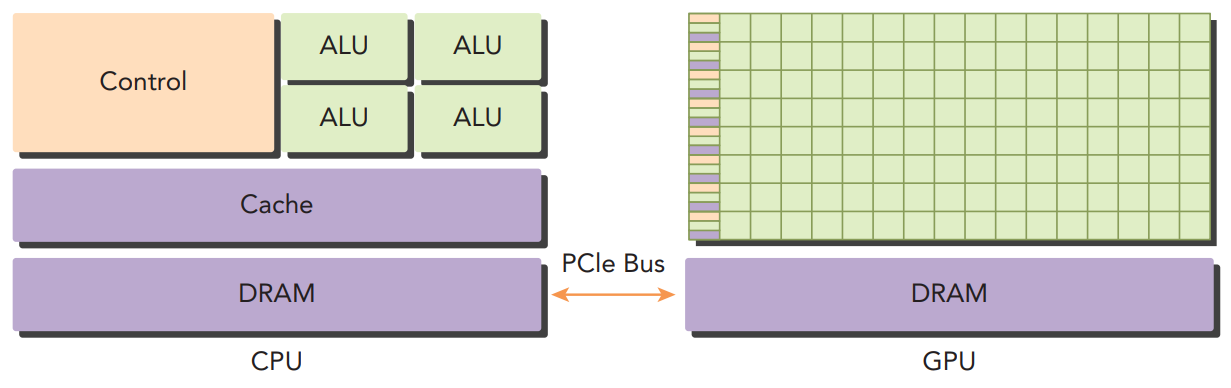
CPU和GPU都是可编程计算器件,从逻辑视角,CUDA扩展了各种编程语言,使得不同开发者可以使用熟悉的编程语言并采用统一模式实现对CPU和GPU的编程。下面我们使用C/C++语言结合一个简单例子来一步步深入理解CUDA的工作原理。
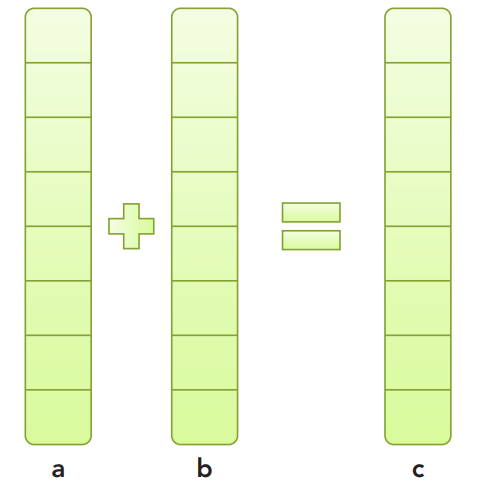
向量加法计算
有两个向量a和b(一维数组),将向量之和计算后放入向量c,如下图所示:
面向CPU编程
如果采用传统的面向CPU的编程,大家应该都会做,示例代码如下:
#include <stdlib.h>
#include <string.h>
#include <time.h>
void sumArraysOnHost(float *A, float *B, float *C, const int N) {
for (int idx=0; idx<N; idx++) {
C[idx] = A[idx] + B[idx];
}
}
void initialData(float *ip,int size) {
// generate different seed for random number
time_t t;
srand((unsigned int) time(&t));
for (int i=0; i<size; i++) {
ip[i] = (float)( rand() & 0xFF )/10.0f;
}
}
int main(int argc, char **argv) {
int nElem = 1024;
size_t nBytes = nElem * sizeof(float);
float *h_A, *h_B, *h_C;
h_A = (float *)malloc(nBytes);
h_B = (float *)malloc(nBytes);
h_C = (float *)malloc(nBytes);
initialData(h_A, nElem);
initialData(h_B, nElem);
sumArraysOnHost(h_A, h_B, h_C, nElem);
free(h_A);
free(h_B);
free(h_C);
return(0);
}
面向CUDA编程
向量加法是一个典型的SIMD计算任务,向量a和b中相同下标元素相加时,不会影响其它下标元素的相加,不同下标元素可以并行相加,因此非常适合使用CUDA中的GPU来计算。那么如何指挥GPU来完成这个计算任务?
1. GPU线程模型与核函数
GPU是由大量的计算核组成的,这些核上执行的计算任务就是线程。从CUDA编程模型的角度上看,这些线程先组合成一个个块(Block),再由这些块组合成一个网格(Grid)。每个Grid对应一个核函数(Kernel function),核函数就是主机下发给GPU设备进行并行计算的一个任务,如这里的向量加法:
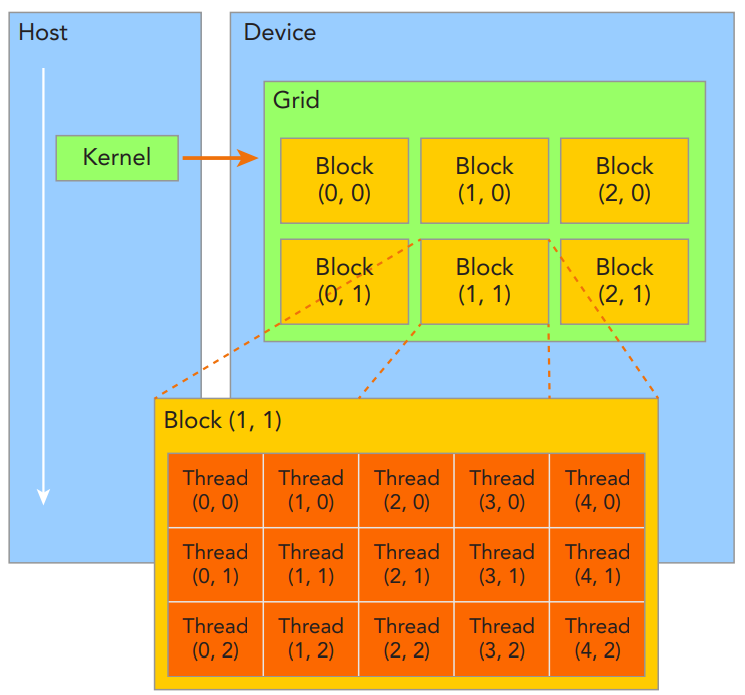
CUDA编程模型中Block和Grid最多有三个维度,上图以二维示例;每个核函数对应的Grid/Block的维数和每维具体数值是由开发者在下发核函数给设备时指定的。
Grid/Block中每个线程执行的指令是相同的,那么怎么让这线程操作不同的数据对象呢?CUDA在编程语言中提供了内置变量,每个线程通过访问这些内置变量可以得到不同的信息,例如各自的线程ID和块ID。
为了简单起见,这里我们可以这样设计GPU中的线程模型:Grid和Block都是一维的,且Block中包含的线程个数和每个向量的元素个数相同,这样Grid中其实只有一个Block。那么我们通过CUDA的内核变量threadIdx.x就可以获得每个运行线程的唯一标识,并且这个标识和向量下标完全相同。因此可以这样编写我们的核函数:
__global__ void sumArraysOnGPU(float *A, float *B, float *C) {
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
注意,这里函数前加了__global__标记,这就告诉编译器,这个函数是由主机侧调用且在设备侧执行的,而非在主机侧执行。同时这里的变量A、B、C都指向设备内存,而非主机内存。可以想象,这个函数最终会在多个GPU计算核上同时执行,每个核访问threadIdx.x时得到的是不同的向量下标,因此后续的加法运算便是针对不同的向量元素进行的。
主机侧调用函核数时需要指定Grid和Block向量,CUDA编程语言中采用kernel_function«<Grid, Block»>()进行表达,代码片断如下:
dim3 block (nElem);
dim3 grid (nElem/block.x);
sumArraysOnGPU<<< grid, block >>>(d_A, d_B, d_C);
2. GPU内存模型(分离式)
GPU内部有独立的显存,核函数运行时往往是直接访问显存以提升计算性能,而非访问主机内存。CUDA编程模型中最简单的内存模型是分离式模型,该模型中主机侧程序通过CUDA提供的API对GPU显存进行显式分配/回收,并且在下发核函数前需要先将数据拷贝到GPU显存中,同时在完成核函数计算后要将计算结果从显存拷贝回主机,如下图所示:
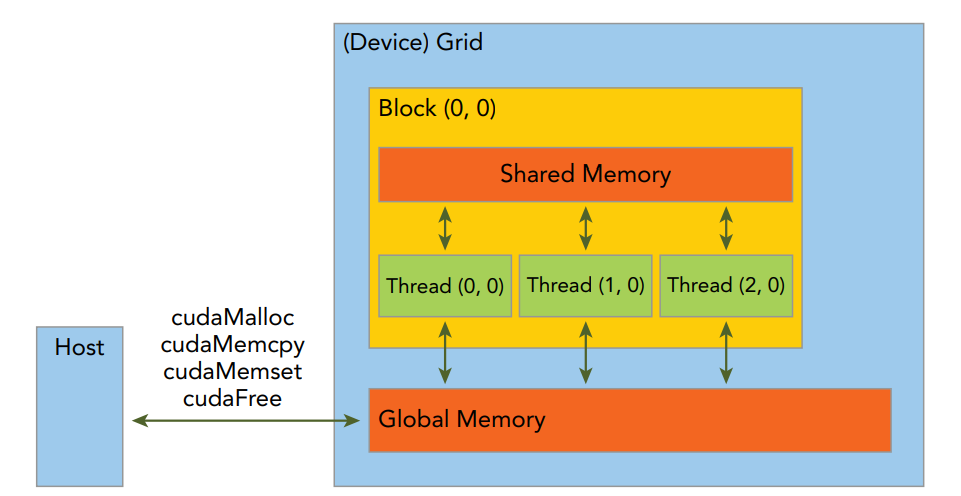
分离模型中,Grid中的所有线程共享显存(Global Memory),主机通过cudaMalloc()分配显存供核函数使用,通过cudaFree()释放显存,并通过cudaMemcpy()在主机和设备之间相互拷贝数据。另外,Shared Memory仅在每个Block内的线程间共享,实际物理存放位置是Block所在SM的L1缓存中,主要用于高性能数据访问场景,本示例中不涉及。
3. 代码汇总
#include <cuda_runtime.h>
#include <stdio.h>
...//省略未修改部分
__global__ void sumArraysOnGPU(float *A, float *B, float *C) {
int i = threadIdx.x;
C[i] = A[i] + B[i];
}
int main(int argc, char **argv) {
// set up device
int dev = 0;
cudaSetDevice(dev);
// set up data size of vectors
int nElem = 32;
printf("Vector size %d\n", nElem);
// malloc host memory
size_t nBytes = nElem * sizeof(float);
float *h_A, *h_B, *gpuRef;
h_A = (float *)malloc(nBytes);
h_B = (float *)malloc(nBytes);
gpuRef = (float *)malloc(nBytes);
// initialize data at host side
initialData(h_A, nElem);
initialData(h_B, nElem);
memset(gpuRef, 0, nBytes);
// malloc device global memory
float *d_A, *d_B, *d_C;
cudaMalloc((float**)&d_A, nBytes);
cudaMalloc((float**)&d_B, nBytes);
cudaMalloc((float**)&d_C, nBytes);
// transfer data from host to device
cudaMemcpy(d_A, h_A, nBytes, cudaMemcpyHostToDevice);
cudaMemcpy(d_B, h_B, nBytes, cudaMemcpyHostToDevice);
// invoke kernel at host side
dim3 block (nElem);
dim3 grid (nElem/block.x);
sumArraysOnGPU<<< grid, block >>>(d_A, d_B, d_C);
// copy kernel result back to host side
cudaMemcpy(gpuRef, d_C, nBytes, cudaMemcpyDeviceToHost);
// free device global memory
cudaFree(d_A);
cudaFree(d_B);
cudaFree(d_C);
// free host memory
free(h_A);
free(h_B);
free(gpuRef);
return(0);
}
最后总结一下,CUDA是入门容易、精通难,特别是性能调优,对底层原理掌握的深入程度决定了程序运行性能,后续会进一步对CUDA执行模型、复杂内存模型等进行介绍和分析,happy hacking cuda~