
这里我们以SPDK前端配置成vhost-blk、后端配置成NVMe SSD场景为例,来分析SPDK的IO栈和线程模型。
IO栈对比与时延分析
我们先来对比一下qemu使用普通内核NVMe驱动和使用SPDK vhost时IO栈的差别,如下图所示:
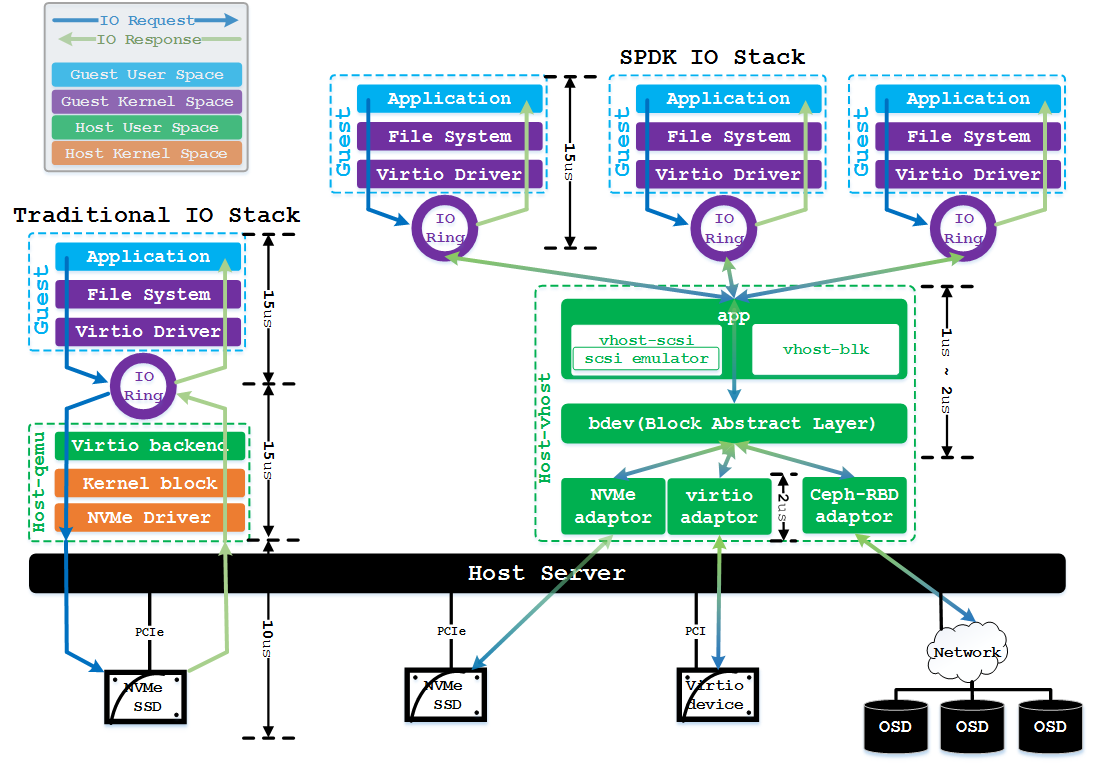
无论使用传统内核NVMe驱动,还是使用vhost,虚拟机内部的IO处理流程都是一样的:IO请求下发时需要从用户态应用程序中切换到内核态,并穿过文件系统和virtio-blk驱动后,才能借助IO环(IO Ring)将请求信息传递给虚拟设备进行处理;虚拟设备处理完成后,以中断方式通知虚拟机,虚拟机内进过驱动和文件系统的回调后,最终唤醒应用程序返回用户态继续执行业务逻辑。在intel Xeon E5620@2.4GHz服务器上的测试结果表明,虚拟机内部的请求下发与响应处理总时延约15us。
针对传统内核NVMe驱动,qemu进程中io线程负责处理虚拟机下发的IO请求:它通过virtio backend从IO环中取出请求,并将请求通过系统调用传递给内核块层和NVMe驱动层进行处理,最后由NVMe驱动将请求通过Queue Pair(类似IO环)交由物理NVMe控制器进行处理;NVMe控制器处理完成后以物理中断方式通知qemu io线程,由它将响应放入虚拟机IO环中并以虚拟中断通知虚拟机请求完成。在此我们看到,qemu中总共的处理时延约15us,而NVMe硬件(华为ES3000 NVMe SSD)上的处理时延才10us(读请求)。
针对SPDK vhost,qemu进程不参与IO请求的处理(仅在初始化时起作用),所有虚拟机下发的IO请求均由vhost进程处理。vhost进程以轮循的方式不断从IO环中取出请求(意味着虚拟机下发IO请求时,不用通知虚拟设备),对于取出的每个请求,vhost将其以任务方式交给bdev抽象层进行处理;bdev根据后端设备的类型来选择不同的驱动进行处理,例如对于NVMe设备,将使用用户态的NVMe驱动在用户空间完成对Queue Pair的操作。vhost进程同样会轮循物理NVMe设备的Queue Pair,如果有响应例会立刻进行处理,而无须等待物理中断。vhost在处理NVMe响应过程中,会向虚拟机IO环中添加响应,并以虚拟中断方式通知虚拟机。我们可以看到,vhost中绝大部分操作都是在用户态完成的(中断通知虚拟机时会进入内核态通过KVM模块完成),各层时延均非常短,app和bdev抽象层约2us,NVMe用户态驱动约2us。
因此,端到端时延对比来看,我们可以发现传统NVMe IO栈的总时延约40us,而SPDK用户态NVMe IO栈时延不到30us,时延上有25%以上的优化。另一方面,在吞吐量(IOPS)方面,如果我们给virtio-blk设备配置多队列(确保虚拟机IO压力足够),并在后端NVMe设备不成为瓶颈的前提下,传统NVMe IO栈在单个qemu io线程处理时,最多能达到20万IOPS,而SPDK vhost在单线程处理时可达100万IOPS,同等CPU开销下,吞吐量上有5倍以上的性能提升。传统NVMe IO栈在处理多队列模型时,相比单队列模型,减少了线程间通知开销,一次通知可以处理多个IO请求,因此多队列相比单队列模型会有较大的IOPS提升;而vhost得益于全用户态及轮循模式,进一步减少了内核切换和通知开销,带来了吞吐量的大幅提升。
线程模型分析
在了解了SPDK的IO栈之后,我们进一步来分析一下vhost进程的线程模型,如下图所示。图中示例场景为,一台服务器上插了一张NVMe SSD卡,卡上划分了三个namespace;三个namespace分别配给了三台虚拟机的vhost-user-blk-pci设备。
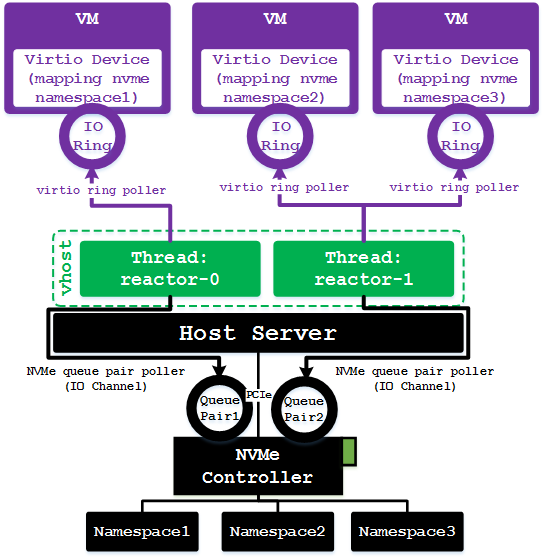
vhost进程启动时可以配置多个轮循线程(reactor),每个线程绑定一个物理CPU。在示例场景下,我们假设配置了两个轮循线程reactor_0和reactor_1,分别对应物理CPU0和物理CPU1。每配置一个vhost-blk设备时,同样要为该设备绑定物理核,并且只能绑定到一个物理核上,例如这里我们假设vm1的vhost-blk设备绑定到CPU0,vm2和vm3绑定到CPU1。那么reactor_0将轮循vm1中vhost-blk的IO环,reactor_1将依次轮循vm2和vm3的IO环。
vhost线程在操作相同NVMe控制器下的namespace时,不同的vhost线程会申请不同的IO Channel(实际对应NVMe Queue Pair,作用类似虚拟机IO环),并且每个线程都会轮循各自申请的IO Channel中的响应消息。例如图中reactor_0会向NVMe控制器申请QueuePair1,并在轮循过程中注册对该QueuePair的poller函数(负责从中取响应);reactor_1则会向NVMe控制器申请QueuePair2并轮循该QueuePair。如此一来,就能提升对后端NVMe设备的并发访问度,充分发挥物理设备的吞吐量优势。
综上所述,
- 每个vhost线程都会轮循若干个vhost设备的IO环(一个vhost设备无论有多少个环,都只会在一个线程中处理),并且会向有操作述求的物理存储控制器(例如NVMe控制器、virtio-blk控制器、virtio-scsi控制器等)申请一个独立的IO Channel(IO环可以理解为对前端虚拟机呈现的一个IO Channel)并对其进行轮循。
- 无论是前端虚拟机IO环,还是后端IO Channel,都只会在一个vhost线程中被轮循,因此这就避免了多线程并发操作同一个对象,可以通过无锁的方式操作IO环或IO Channel。
- 针对前端虚拟机来说,一个vhost设备无论有多少个环,都只会在一个vhost线程中处理。这种设计上的约束虽说可以简化实现,但也带来了吞吐量性能扩展上的限制,即一个vhost设备在后端物理存储非瓶颈的前提下,最高的IOPS为100万。因此我们可以考虑将vhost的多个IO环拆分到多个vhost线程中处理,进一步提升吞吐量。
转载请注明:吴斌的博客 » 【SPDK】二、IO栈对比与线程模型