
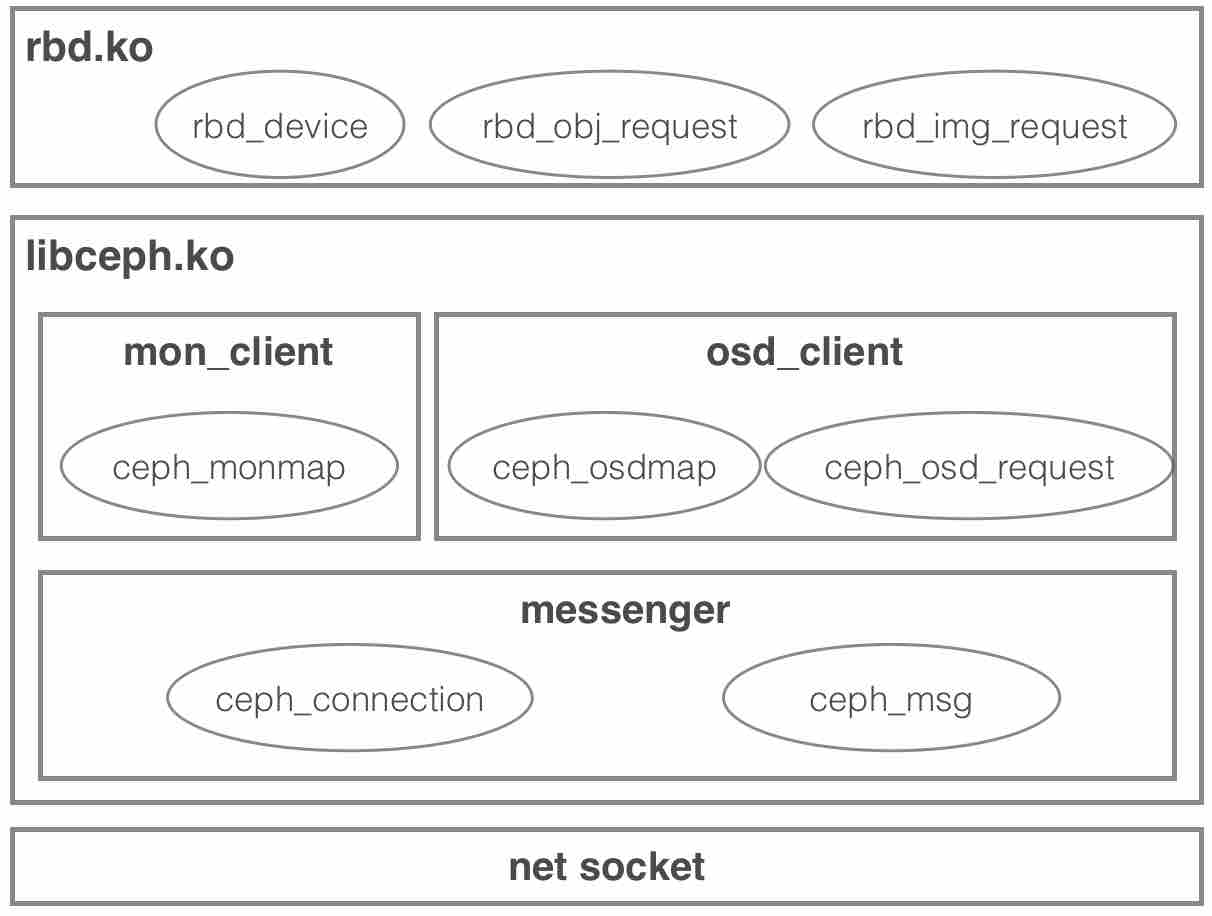
内核RBD驱动整体软件栈如下:
3. RBD块设备IO流程分析
上节我们在分析映射流程时,已经涉及和OSD的交互,但并未深入讨论,因此这里我们将通过IO的处理流程来深入分析其内部原理。
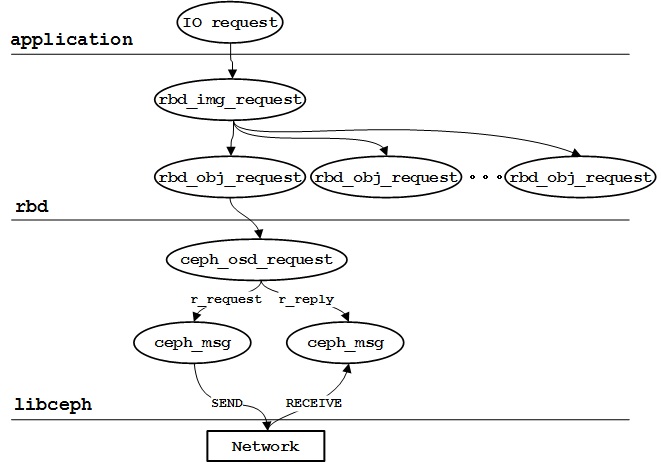
IO流程可分为请求下发和响应返回两个阶段,整体过程如下图所示:
- 应用程序下发的IO请求在rbd层被表达为一个rbd_img_request;每个rbd_img_request会被划分成一个个以4M为粒度的rbd_obj_request(其实我们在上一节分析时已经涉及rbd_obj_request),这些rbd_obj_request对应OSD中存储的对象;通过CRUSH算法计算出存储rbd_obj_request的主OSD后,将rbd_obj_request封装成ceph_osd_request,接着将ceph_osd_request放入一个ceph_msg中并通过lmessenger模块进行发送;
- OSD请求处理完成后回复响应,messenger模块通过ceph_msg接收响应消息,并找到对应的ceph_osd_request,接着就进行回调的处理;
3.1. IO下发:rbd_request_fn
IO处理的核心函数是rbd_request_fn,其调用栈大体如下:
rbd_request_fn[*]
|-rbd_img_request_create
|-rbd_img_request_fill
| |-rbd_obj_request_create
| |-rbd_osd_req_create
| |-osd_req_op_extent_osd_data_bio
| \-rbd_osd_req_format_write(or read)
\-rbd_img_request_submit
|-__register_request
|-__map_request
\-__send_queued
linux/drivers/block/rbd.c:
/*当应用向RBD块设备下发读写请求时,最终会调用该函数;
q代表请求所在的请求队列*/
static void rbd_request_fn(struct request_queue *q)
__releases(q->queue_lock) __acquires(q->queue_lock)
{
struct rbd_device *rbd_dev = q->queuedata; /*队列私有数据,初始化时指定,代表rbd_dev对象*/
struct request *rq;
int result;
/*通过一个大循环,不断调用blk_fetch_request从请求队列中取出待处理的请求rq*/
while ((rq = blk_fetch_request(q))) {
bool write_request = rq_data_dir(rq) == WRITE; /*判断请求读写类型*/
struct rbd_img_request *img_request;
u64 offset;
u64 length;
...
offset = (u64) blk_rq_pos(rq) << SECTOR_SHIFT; /*计算请求起始位置,从扇区转换成字节*/
length = (u64) blk_rq_bytes(rq); /*获取请求大小*/
...
result = -ENOMEM;
/*针对每个rq,这里会生成一个rbd_img_request与之对应;其内部会记录请求起始位置、长度和读写类型等信息*/
img_request = rbd_img_request_create(rbd_dev, offset, length, write_request);
if (!img_request)
goto end_request;
/*绑定img_request和rq之间的关系*/
img_request->rq = rq;
/*向img_request中填入bio信息,下面将展开分析*/
result = rbd_img_request_fill(img_request, OBJ_REQUEST_BIO, rq->bio);
/*将img_request递交给底层libceph过行网络发送,下面将展开分析*/
if (!result)
result = rbd_img_request_submit(img_request);
...
}
}
3.1.1. rbd_img_request_fill
rbd_request_fn
|-rbd_img_request_create
|-rbd_img_request_fill[*]
| |-rbd_obj_request_create
| |-rbd_osd_req_create
| |-osd_req_op_extent_osd_data_bio
| \-rbd_osd_req_format_write(or read)
\-rbd_img_request_submit
|-__register_request
|-__map_request
\-__send_queued
由于每个RBD设备会以4M为粒度划分成一个个对象,所以对每个RBD设备的请求(image request)会转换成若干对象请求(object request)。rbd_img_request_fill的主要作用就是完成image request到object request的转换:
linux/drivers/block/rbd.c:
static int rbd_img_request_fill(struct rbd_img_request *img_request,
enum obj_request_type type,void *data_desc)
{
struct rbd_device *rbd_dev = img_request->rbd_dev;
struct rbd_obj_request *obj_request = NULL;
struct rbd_obj_request *next_obj_request;
bool write_request = img_request_write_test(img_request); /*是否为写请求*/
struct bio *bio_list = 0;
unsigned int bio_offset = 0;
struct page **pages = 0;
u64 img_offset;
u64 resid;
u16 opcode;
opcode = write_request ? CEPH_OSD_OP_WRITE : CEPH_OSD_OP_READ;
img_offset = img_request->offset; /*image request对应的请求偏移*/
resid = img_request->length; /*image request对应的请求长度*/
rbd_assert(resid > 0);
if (type == OBJ_REQUEST_BIO) {/*这里主要考虑bio类型的请求*/
bio_list = data_desc;
rbd_assert(img_offset == bio_list->bi_sector << SECTOR_SHIFT);
} else {
...
}
while (resid) {
struct ceph_osd_request *osd_req;
const char *object_name;
u64 offset;
u64 length;
/*根据image request偏移位置计算对象名称*/
object_name = rbd_segment_name(rbd_dev, img_offset);
...
/*4M对象内的偏移*/
offset = rbd_segment_offset(rbd_dev, img_offset);
/*4M对象内的长度*/
length = rbd_segment_length(rbd_dev, img_offset, resid);
/*新建一个object request*/
obj_request = rbd_obj_request_create(object_name, offset, length, type);
/* object request has its own copy of the object name */
rbd_segment_name_free(object_name);
if (!obj_request)
goto out_unwind;
/*
* set obj_request->img_request before creating the
* osd_request so that it gets the right snapc
*/
rbd_img_obj_request_add(img_request, obj_request);
if (type == OBJ_REQUEST_BIO) {
unsigned int clone_size;
rbd_assert(length <= (u64)UINT_MAX);
clone_size = (unsigned int)length;
/*克隆object request对应的bio段*/
obj_request->bio_list =
bio_chain_clone_range(&bio_list,
&bio_offset,
clone_size,
GFP_ATOMIC);
...
} else {
...
}
/*针对object request创建底层的osd request*/
osd_req = rbd_osd_req_create(rbd_dev, write_request, obj_request);
...
obj_request->osd_req = osd_req;
obj_request->callback = rbd_img_obj_callback; /*请求处理完成时的回调*/
rbd_img_request_get(img_request);
/*将object request的bio信息填入到osd request的extent中*/
osd_req_op_extent_init(osd_req, 0, opcode, offset, length, 0, 0);
if (type == OBJ_REQUEST_BIO)
osd_req_op_extent_osd_data_bio(osd_req, 0, obj_request->bio_list, length);
else
...
if (write_request) /*这里将ceph_osd_request中的信息填入到ceph_msg(r_request)中*/
rbd_osd_req_format_write(obj_request);
else
rbd_osd_req_format_read(obj_request);
obj_request->img_offset = img_offset;
/*更新偏移和长度,并继续循环*/
img_offset += length;
resid -= length;
}
return 0;
...
}
这里我们深入看看ceph_osd_request的结构定义,它体现了OSD对客户端呈现的操作接口:
linux/include/linux/ceph/osd_client.h:
struct ceph_osd_request {
u64 r_tid; /* unique for this client */
...
struct ceph_osd *r_osd; /*请求对应的OSD*/
...
struct ceph_msg *r_request, *r_reply; /*请求对应的发送消息和响应接收消息*/
...
/* request osd ops array */ /*每个请求由若干操作组成,如CEPH_OSD_OP_READ*/
unsigned int r_num_ops;
struct ceph_osd_req_op r_ops[CEPH_OSD_MAX_OP];
...
};
/*OSD提供了许多不同的操作,均以CEPH_OSD_OP_打头。例如对于读请求,包含一个CEPH_OSD_OP_READ操作,
操作对象extent中保存对象访问的偏移、长度和数据存储内存的位置信息;对于写请求,
包含一个CEPH_OSD_OP_WRITE,操作对象也在extent中*/
struct ceph_osd_req_op {
u16 op; /* CEPH_OSD_OP_* */
u32 payload_len;
union {
struct ceph_osd_data raw_data_in;
struct {
u64 offset, length;
u64 truncate_size;
u32 truncate_seq;
struct ceph_osd_data osd_data;
} extent; /*CEPH_OSD_OP_READ/WRITE之类的操作使用*/
struct {
const char *class_name;
const char *method_name;
struct ceph_osd_data request_info;
struct ceph_osd_data request_data;
struct ceph_osd_data response_data;
__u8 class_len;
__u8 method_len;
__u8 argc;
} cls; /*CEPH_OSD_OP_CALL操作使用*/
struct {
u64 cookie;
u64 ver;
u32 prot_ver;
u32 timeout;
__u8 flag;
} watch;
};
};
enum ceph_osd_data_type {
CEPH_OSD_DATA_TYPE_NONE = 0,
CEPH_OSD_DATA_TYPE_PAGES,
CEPH_OSD_DATA_TYPE_PAGELIST,
CEPH_OSD_DATA_TYPE_BIO,
};
/*数据保存内存位置可以通过page数组、pagelist和bio三种方式表达*/
struct ceph_osd_data {
enum ceph_osd_data_type type;
union {
struct {
struct page **pages;
u64 length;
u32 alignment;
bool pages_from_pool;
bool own_pages;
};
struct ceph_pagelist *pagelist;
struct {
struct bio *bio; /* list of bios */
size_t bio_length; /* total in list */
};
};
};
3.1.2. rbd_img_request_submit
rbd_request_fn
|-rbd_img_request_create
|-rbd_img_request_fill
| |-rbd_obj_request_create
| |-rbd_osd_req_create
| |-osd_req_op_extent_osd_data_bio
| \-rbd_osd_req_format_write(or read)
\-rbd_img_request_submit[*]
|-__register_request
|-__map_request
\-__send_queued
完成object request对象的成生后,rbd_image_request_submit调用rbd_obj_request_submit,最终来到libceph中的ceph_osdc_start_request,它的主要作用就是根据访问对象、OSDMap和CRUSH算法计算出对象所在PG对应的主OSD节点,并将该object request对应的osd request的r_request消息通过网络发送给该OSD处理:
linux/net/ceph/osd_client.c:
int ceph_osdc_start_request(struct ceph_osd_client *osdc,
struct ceph_osd_request *req, bool nofail)
{
int rc = 0;
down_read(&osdc->map_sem);
mutex_lock(&osdc->request_mutex);
/*将该osd请求添加到osdc中*/
__register_request(osdc, req);
req->r_sent = 0;
req->r_got_reply = 0;
/*通过CRUSH算法及OSDMap映射当前osd请求到OSD节点,有关CRUSH的原理可以参考相关论文*/
rc = __map_request(osdc, req, 0);
if (rc < 0) {
...
}
if (req->r_osd == NULL) {
dout("send_request %p no up osds in pg\n", req);
ceph_monc_request_next_osdmap(&osdc->client->monc);
} else {
/*将该请求发送给OSD节点*/
__send_queued(osdc);
}
rc = 0;
out_unlock:
mutex_unlock(&osdc->request_mutex);
up_read(&osdc->map_sem);
return rc;
}
3.2. IO返回
IO请求通过网络发送给OSD节点后,OSD节点在处理完成后会回复响应,响应的处理逻辑在客户端创建OSD对象时指定:
linux/net/ceph/osd_client.c:
static struct ceph_osd *create_osd(struct ceph_osd_client *osdc, int onum)
{
struct ceph_osd *osd;
osd = kzalloc(sizeof(*osd), GFP_NOFS);
if (!osd)
return NULL;
atomic_set(&osd->o_ref, 1);
osd->o_osdc = osdc;
osd->o_osd = onum;
RB_CLEAR_NODE(&osd->o_node);
INIT_LIST_HEAD(&osd->o_requests);
INIT_LIST_HEAD(&osd->o_linger_requests);
INIT_LIST_HEAD(&osd->o_osd_lru);
osd->o_incarnation = 1;
ceph_con_init(&osd->o_con, osd, &osd_con_ops, &osdc->client->msgr);
INIT_LIST_HEAD(&osd->o_keepalive_item);
return osd;
}
static const struct ceph_connection_operations osd_con_ops = {
.get = get_osd_con,
.put = put_osd_con,
.dispatch = dispatch, /*消息处理逻辑*/
.get_authorizer = get_authorizer,
.verify_authorizer_reply = verify_authorizer_reply,
.invalidate_authorizer = invalidate_authorizer,
.alloc_msg = alloc_msg,
.fault = osd_reset,
};
static void dispatch(struct ceph_connection *con, struct ceph_msg *msg)
{
struct ceph_osd *osd = con->private;
struct ceph_osd_client *osdc;
int type = le16_to_cpu(msg->hdr.type);
if (!osd)
goto out;
osdc = osd->o_osdc;
switch (type) {
case CEPH_MSG_OSD_MAP:
ceph_osdc_handle_map(osdc, msg);
break;
case CEPH_MSG_OSD_OPREPLY:
handle_reply(osdc, msg, con);
break;
case CEPH_MSG_WATCH_NOTIFY:
handle_watch_notify(osdc, msg);
break;
default:
pr_err("received unknown message type %d %s\n", type,
ceph_msg_type_name(type));
}
out:
ceph_msg_put(msg);
}
在handle_reply中会从osd request到object request,再到image request,层层调用回调并处理已经结束的IO请求。