
内核RBD驱动整体软件栈如下:
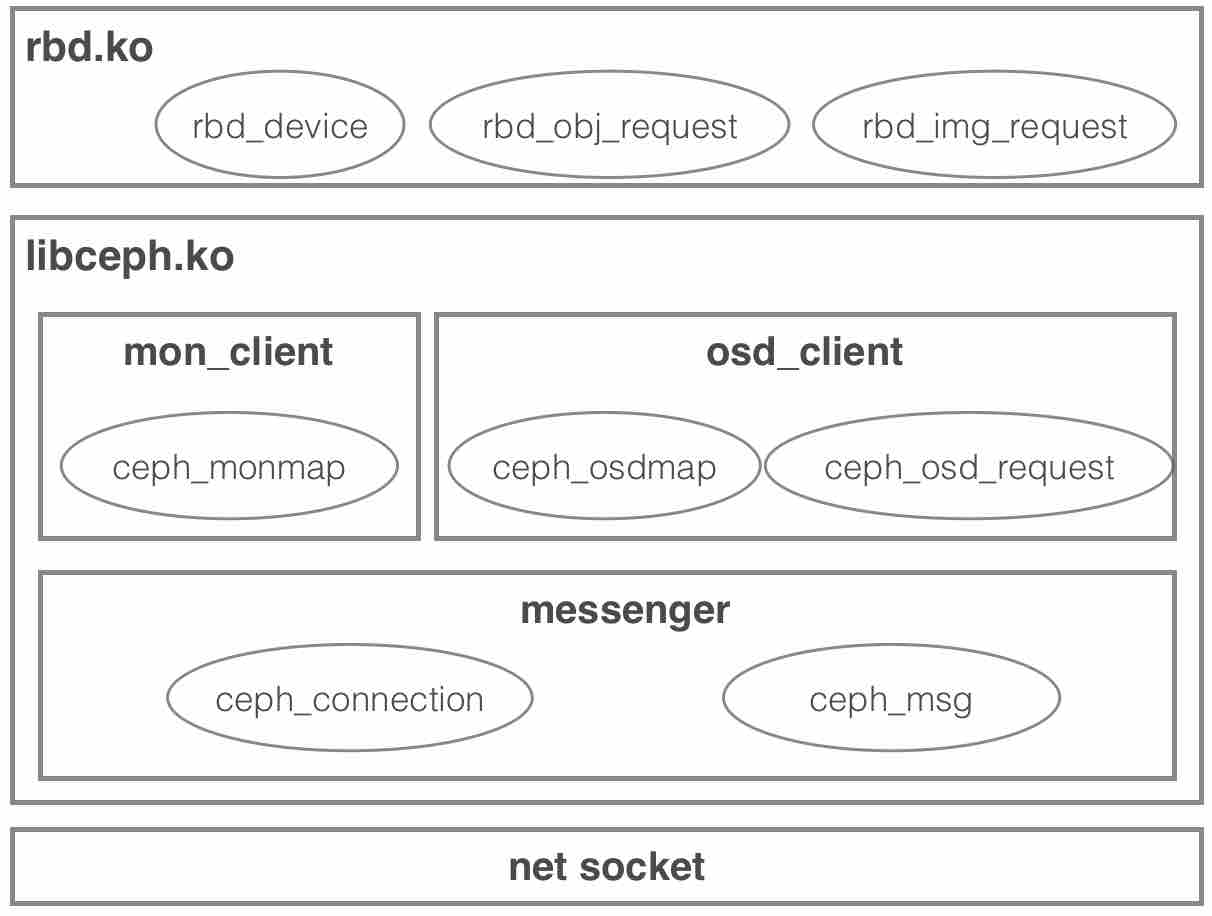
rbd工具通过map子命令映射产生一个可使用的内核块设备,其本质原理是由rbd工具往sysfs(“/sys/bus/rbd/add”)内核文件接口中写入待创建块设备的信息(例如前文实例写入的内容为”9.22.115.154:6789 name=amdin,key=client, wbpool wb -“,其中9.22.115.154为主monitor的IP),内核在处理这个写入请求时会调用由RBD驱动事先注册好的处理函数来生成一个内核块设备对象。
2. RBD块设备映射流程分析
我们先来看看rbd模块加载初始化时完成了哪些初始化动作:
linux/drivers/block/rbd.c:
static int __init rbd_init(void)
{
int rc;
/*首先检查rbd驱动依赖的底层libceph驱动的兼容性*/
if (!libceph_compatible(NULL)) {
rbd_warn(NULL, "libceph incompatibility (quitting)");
return -EINVAL;
}
/*初始化rbd驱动中使用的内存分配器*/
rc = rbd_slab_init();
if (rc)
return rc;
/*sysfs文件接口初始化,为用户态rbd工具暴露访问接口*/
rc = rbd_sysfs_init();
if (rc)
rbd_slab_exit();
else
pr_info("loaded " RBD_DRV_NAME_LONG "\n");
return rc;
}
module_init(rbd_init);
linux/drivers/block/rbd.c:
/*
* create control files in sysfs
* /sys/bus/rbd/...
*/
static int rbd_sysfs_init(void)
{
int ret;
ret = device_register(&rbd_root_dev);
if (ret < 0)
return ret;
/*根据rbd_bus_type定义的信息在/sys/bus/下生成子目录*/
ret = bus_register(&rbd_bus_type);
if (ret < 0)
device_unregister(&rbd_root_dev);
return ret;
}
static struct bus_attribute rbd_bus_attrs[] = {
__ATTR(add, S_IWUSR, NULL, rbd_add), /*对rbd目录下的add文件进行写操作时将调用rbd_add*/
__ATTR(remove, S_IWUSR, NULL, rbd_remove), /*对rbd目录下的remove文件进行写操作时将调用rbd_remove*/
__ATTR_NULL
};
static struct bus_type rbd_bus_type = {
.name = "rbd", /* /sys/bus/成生的子目录名 */
.bus_attrs = rbd_bus_attrs,
};
下面我们顺着本文开头给出的软件栈从上至下(rbd->libceph)深入分析rbd_add函数,看看内核RBD驱动是如何进行块设备的生成的:
linux/drivers/block/rbd.c:
/*用户态工具往/sys/bus/rbd/add中写入RBD设备信息,内核在处理该写入请求时就会
调用这里的rbd_add,其中bus就是/sys/bus/rbd对象,buf中存放用户态工具写入的
字符串,如"9.22.115.154:6789 name=amdin,key=client, wbpool wb -",
count为写入的字符串长度*/
static ssize_t rbd_add(struct bus_type *bus,
const char *buf, size_t count)
{
struct rbd_device *rbd_dev = NULL;
struct ceph_options *ceph_opts = NULL;
struct rbd_options *rbd_opts = NULL;
struct rbd_spec *spec = NULL;
struct rbd_client *rbdc;
struct ceph_osd_client *osdc;
bool read_only;
int rc = -ENOMEM;
...
/*首先对用户态写入的字符串进行解析,结果返回到ceph_opts,rbd_opt和spec中:
(1)ceph_opts中保存ceph集群相关信息,针对前文示例,ceph_opts.mon_addr中将保存
"9.22.115.154:6789";ceph_opts.name为"admin",代表访问ceph集群的角色名称;
ceph_opts.key对应系统配置中的"ceph.client.admin.keyring",为登陆密钥。
(2)rbd_opt中包含当前rbd设备是否只读,针对前文示例,rbd_opt.read_only为false。
(3)spec中包含当前rbd设备的详细描述信息,针对示例,spec.pool_name为"wb_pool",
spec.image_name为"wb",spec.snap_name为"-",表示无快照*/
/* parse add command */
rc = rbd_add_parse_args(buf, &ceph_opts, &rbd_opts, &spec);
if (rc < 0)
goto err_out_module;
read_only = rbd_opts->read_only;
kfree(rbd_opts);
rbd_opts = NULL; /* done with this */
/*接着根据ceph集群配置ceph_opts在当前客户端查找是否已生成rbd_client(对应一个ceph_client,
内部包含mon_client和osd_client);如果未找到则生成一个新的rbd_client,并建立会话(完成认证、获
取monmap和osdmap等一系统初始化动作)*/
rbdc = rbd_get_client(ceph_opts);
if (IS_ERR(rbdc)) {
rc = PTR_ERR(rbdc);
goto err_out_args;
}
/*从ceph集群返回的osdmap中获取当前pool对应的id*/
/* pick the pool */
osdc = &rbdc->client->osdc;
rc = ceph_pg_poolid_by_name(osdc->osdmap, spec->pool_name);
if (rc < 0)
goto err_out_client;
spec->pool_id = (u64)rc;
...
/*创建内核中的rbd_dev对象*/
rbd_dev = rbd_dev_create(rbdc, spec);
if (!rbd_dev)
goto err_out_client;
rbdc = NULL; /* rbd_dev now owns this */
spec = NULL; /* rbd_dev now owns this */
/*从ceph集群中查询当前rbd设备(image)的元数据信息,即从rbd_id.[rbd设备名]中获知image id,并从
rbd_header.[image id]的omap中获得设备大小,分片大小等信息*/
rc = rbd_dev_image_probe(rbd_dev, true);
if (rc < 0)
goto err_out_rbd_dev;
...
/*根据ceph集群返回的rbd信息,完成对rbd_dev的设置,并通过内核块层接口生成新的块设备对象*/
rc = rbd_dev_device_setup(rbd_dev);
if (rc) {
rbd_dev_image_release(rbd_dev);
goto err_out_module;
}
return count;
...
}
2.1. rbd_get_client
rbd_get_client[*]
\-rbd_client_create
|-ceph_create_client
| |-ceph_messenger_init
| |-ceph_monc_init
| \-ceph_osdc_init
\_ceph_open_session
|-ceph_monc_open_session
| \-__open_session
| |-ceph_con_open
| |-ceph_auth_build_hello
| \-__send_prepared_auth_request
\-wait_event_interruptible_timeout
针对同一个rados集群,每个客户端节点都会在内核中生成一个rbd_client对象,用来和该rados集群进行会话;在一个客户端节点上,如果针对同一个rados集群创建了多个RBD设备,那么这些RBD设备会共用同一个rbd_client。下面我们看看rbd_get_client的内部实现:
linux/drivers/block/rbd.c:
/*
* Get a ceph client with specific addr and configuration, if one does
* not exist create it. Either way, ceph_opts is consumed by this
* function.
*/
static struct rbd_client *rbd_get_client(struct ceph_options *ceph_opts)
{
struct rbd_client *rbdc;
rbdc = rbd_client_find(ceph_opts); /*在全局链表rbd_client_list中根据ceph_opts的集群信息查找rbd_client*/
if (rbdc) /* using an existing client */
ceph_destroy_options(ceph_opts); /*如果找到相同的rbd_client(对应同一个rados集群),则复用该对象,同时销毁ceph_opts*/
else
rbdc = rbd_client_create(ceph_opts); /*如果没有找到相同的rbd_client,则新建一个并添加到rbd_client_list中*/
return rbdc;
}
接着看rbd_client_create:
linux/drivers/block/rbd.c:
/*rbd_client代表rbd客户端实例,多个rbd设备可共用一个客户端实例;其内部主要包含一个ceph_client对象*/
/*
* an instance of the client. multiple devices may share an rbd client.
*/
struct rbd_client {
struct ceph_client *client;
struct kref kref;
struct list_head node;
};
/*
* Initialize an rbd client instance. Success or not, this function
* consumes ceph_opts.
*/
static struct rbd_client *rbd_client_create(struct ceph_options *ceph_opts)
{
struct rbd_client *rbdc;
int ret = -ENOMEM;
rbdc = kmalloc(sizeof(struct rbd_client), GFP_KERNEL);
...
/*调用libceph.ko中的函数创建ceph_client对象*/
rbdc->client = ceph_create_client(ceph_opts, rbdc, 0, 0);
...
/*调用libceph.ko中的函数打开ceph_client对象的会话,基于该会话可以和rados集群(monitor or OSD)进行通信*/
ret = ceph_open_session(rbdc->client);
...
spin_lock(&rbd_client_list_lock);
list_add_tail(&rbdc->node, &rbd_client_list);
spin_unlock(&rbd_client_list_lock);
...
return rbdc;
...
}
下面我们再深入一层,看看libceph中ceph_client的相关实现,但不会深入到messenger模块中(复杂性较高),我们在2.1.3节会总结一下对messenger模块的使用方法(API)。对于messenger的分析我们将放到单独的博文中介绍。
2.1.1. rbd_get_client -> ceph_create_client
rbd_get_client
\-rbd_client_create
|-ceph_create_client[*]
| |-ceph_messenger_init
| |-ceph_monc_init
| \-ceph_osdc_init
\_ceph_open_session
|-ceph_monc_open_session
| \-__open_session
| |-ceph_con_open
| |-ceph_auth_build_hello
| \-__send_prepared_auth_request
\-wait_event_interruptible_timeout
linux/include/linux/ceph/libceph.h:
/*
* per client state
*
* possibly shared by multiple mount points, if they are
* mounting the same ceph filesystem/cluster.
*/
struct ceph_client {
...
/*每个ceph_client包含一个messenger实例、一个mon_client实例和一个osd_client实例:
(1)messenger实例描述了与网络通信相关的信息,属于messenger模块,是ceph客户端基于socket封装的网络服务层;
(2)mon_client实例是专门用来与monitor通信的客户端;
(3)osd_client实例是专门用来与所有osd通信的客户端。*/
struct ceph_messenger msgr; /* messenger instance */
struct ceph_mon_client monc;
struct ceph_osd_client osdc;
...
};
linux/net/ceph/ceph_common.c:
/*ceph_create_client创建ceph_client对象并对其内部的messenger、mon_client、osd_client进行初始化*/
/*
* create a fresh client instance
*/
struct ceph_client *ceph_create_client(struct ceph_options *opt, void *private,
unsigned int supported_features, unsigned int required_features)
{
struct ceph_client *client;
struct ceph_entity_addr *myaddr = NULL;
int err = -ENOMEM;
client = kzalloc(sizeof(*client), GFP_KERNEL);
if (client == NULL)
return ERR_PTR(-ENOMEM);
client->private = private;
client->options = opt;
...
/* msgr */
if (ceph_test_opt(client, MYIP))
myaddr = &client->options->my_addr;
ceph_messenger_init(&client->msgr, myaddr, client->supported_features,
client->required_features, ceph_test_opt(client, NOCRC));
/* subsystems */
err = ceph_monc_init(&client->monc, client);
if (err < 0)
goto fail;
err = ceph_osdc_init(&client->osdc, client);
if (err < 0)
goto fail_monc;
return client;
...
}
接着我们可以浏览一下messenger、mon_client、osd_client的初始化,重点关注注释部分:
linux/include/linux/ceph/messenger.h:
struct ceph_messenger {
struct ceph_entity_inst inst; /* my name+address */
struct ceph_entity_addr my_enc_addr;
atomic_t stopping;
bool nocrc;
/*
* the global_seq counts connections i (attempt to) initiate
* in order to disambiguate certain connect race conditions.
*/
u32 global_seq;
spinlock_t global_seq_lock;
u32 supported_features;
u32 required_features;
};
linux/net/ceph/messenger.c:
/*
* initialize a new messenger instance
*/
void ceph_messenger_init(struct ceph_messenger *msgr,
struct ceph_entity_addr *myaddr,
u32 supported_features,
u32 required_features,
bool nocrc)
{
msgr->supported_features = supported_features;
msgr->required_features = required_features;
spin_lock_init(&msgr->global_seq_lock);
if (myaddr)
msgr->inst.addr = *myaddr;
/* select a random nonce */
msgr->inst.addr.type = 0;
get_random_bytes(&msgr->inst.addr.nonce, sizeof(msgr->inst.addr.nonce));
encode_my_addr(msgr);
msgr->nocrc = nocrc;
atomic_set(&msgr->stopping, 0);
dout("%s %p\n", __func__, msgr);
}
linux/include/linux/ceph/mon_client.h:
struct ceph_mon_client {
struct ceph_client *client;
struct ceph_monmap *monmap;
struct mutex mutex;
struct delayed_work delayed_work;
struct ceph_auth_client *auth;
struct ceph_msg *m_auth, *m_auth_reply, *m_subscribe, *m_subscribe_ack;
int pending_auth;
bool hunting;
int cur_mon; /* last monitor i contacted */
unsigned long sub_sent, sub_renew_after;
struct ceph_connection con;
/* pending generic requests */
struct rb_root generic_request_tree;
int num_generic_requests;
u64 last_tid;
/* mds/osd map */
int want_mdsmap;
int want_next_osdmap; /* 1 = want, 2 = want+asked */
u32 have_osdmap, have_mdsmap;
};
linux/net/ceph/mon_client.c:
int ceph_monc_init(struct ceph_mon_client *monc, struct ceph_client *cl)
{
int err = 0;
dout("init\n");
memset(monc, 0, sizeof(*monc));
monc->client = cl;
monc->monmap = NULL;
mutex_init(&monc->mutex);
err = build_initial_monmap(monc);
if (err)
goto out;
/* connection */
/* authentication */
monc->auth = ceph_auth_init(cl->options->name, cl->options->key);
...
monc->auth->want_keys =
CEPH_ENTITY_TYPE_AUTH | CEPH_ENTITY_TYPE_MON |
CEPH_ENTITY_TYPE_OSD | CEPH_ENTITY_TYPE_MDS;
/* msgs */
err = -ENOMEM;
monc->m_subscribe_ack = ceph_msg_new(CEPH_MSG_MON_SUBSCRIBE_ACK,
sizeof(struct ceph_mon_subscribe_ack), GFP_NOFS, true);
...
monc->m_subscribe = ceph_msg_new(CEPH_MSG_MON_SUBSCRIBE, 96, GFP_NOFS, true);
...
monc->m_auth_reply = ceph_msg_new(CEPH_MSG_AUTH_REPLY, 4096, GFP_NOFS, true);
...
monc->m_auth = ceph_msg_new(CEPH_MSG_AUTH, 4096, GFP_NOFS, true);
monc->pending_auth = 0;
...
/*mon_client通过底层messenger模块中的connection对象进行网络通信,这里对mon_client使用的connection进行
初始化,并指定其网络层回调函数集为mon_con_ops,用来处理消息回调、网络连接故障等*/
ceph_con_init(&monc->con, monc, &mon_con_ops, &monc->client->msgr);
monc->cur_mon = -1;
monc->hunting = true;
monc->sub_renew_after = jiffies;
monc->sub_sent = 0;
INIT_DELAYED_WORK(&monc->delayed_work, delayed_work);
monc->generic_request_tree = RB_ROOT;
monc->num_generic_requests = 0;
monc->last_tid = 0;
monc->have_mdsmap = 0;
monc->have_osdmap = 0;
monc->want_next_osdmap = 1;
return 0;
...
}
linux/include/linux/ceph/osd_client.h:
struct ceph_osd_client {
struct ceph_client *client;
struct ceph_osdmap *osdmap; /* current map */
struct rw_semaphore map_sem;
struct completion map_waiters;
u64 last_requested_map;
struct mutex request_mutex;
struct rb_root osds; /* osds */
struct list_head osd_lru; /* idle osds */
u64 timeout_tid; /* tid of timeout triggering rq */
u64 last_tid; /* tid of last request */
struct rb_root requests; /* pending requests */
struct list_head req_lru; /* in-flight lru */
struct list_head req_unsent; /* unsent/need-resend queue */
struct list_head req_notarget; /* map to no osd */
struct list_head req_linger; /* lingering requests */
int num_requests;
struct delayed_work timeout_work;
struct delayed_work osds_timeout_work;
mempool_t *req_mempool;
struct ceph_msgpool msgpool_op;
struct ceph_msgpool msgpool_op_reply;
spinlock_t event_lock;
struct rb_root event_tree;
u64 event_count;
struct workqueue_struct *notify_wq;
};
linux/net/ceph/osd_client.c:
int ceph_osdc_init(struct ceph_osd_client *osdc, struct ceph_client *client)
{
int err;
dout("init\n");
osdc->client = client;
osdc->osdmap = NULL;
init_rwsem(&osdc->map_sem);
init_completion(&osdc->map_waiters);
osdc->last_requested_map = 0;
mutex_init(&osdc->request_mutex);
osdc->last_tid = 0;
osdc->osds = RB_ROOT;
INIT_LIST_HEAD(&osdc->osd_lru);
osdc->requests = RB_ROOT;
INIT_LIST_HEAD(&osdc->req_lru);
INIT_LIST_HEAD(&osdc->req_unsent);
INIT_LIST_HEAD(&osdc->req_notarget);
INIT_LIST_HEAD(&osdc->req_linger);
osdc->num_requests = 0;
INIT_DELAYED_WORK(&osdc->timeout_work, handle_timeout);
INIT_DELAYED_WORK(&osdc->osds_timeout_work, handle_osds_timeout);
spin_lock_init(&osdc->event_lock);
osdc->event_tree = RB_ROOT;
osdc->event_count = 0;
schedule_delayed_work(&osdc->osds_timeout_work,
round_jiffies_relative(osdc->client->options->osd_idle_ttl * HZ));
err = -ENOMEM;
osdc->req_mempool = mempool_create_kmalloc_pool(10, sizeof(struct ceph_osd_request));
if (!osdc->req_mempool)
goto out;
err = ceph_msgpool_init(&osdc->msgpool_op, CEPH_MSG_OSD_OP,
OSD_OP_FRONT_LEN, 10, true, "osd_op");
if (err < 0)
goto out_mempool;
err = ceph_msgpool_init(&osdc->msgpool_op_reply, CEPH_MSG_OSD_OPREPLY,
OSD_OPREPLY_FRONT_LEN, 10, true, "osd_op_reply");
if (err < 0)
goto out_msgpool;
err = -ENOMEM;
osdc->notify_wq = create_singlethread_workqueue("ceph-watch-notify");
if (!osdc->notify_wq)
goto out_msgpool;
return 0;
out_msgpool:
ceph_msgpool_destroy(&osdc->msgpool_op);
out_mempool:
mempool_destroy(osdc->req_mempool);
out:
return err;
}
2.1.2. rbd_get_client -> ceph_open_session
rbd_get_client
\-rbd_client_create
|-ceph_create_client
| |-ceph_messenger_init
| |-ceph_monc_init
| \-ceph_osdc_init
\_ceph_open_session[*]
|-ceph_monc_open_session
| \-__open_session
| |-ceph_con_open
| |-ceph_auth_build_hello
| \-__send_prepared_auth_request
\-wait_event_interruptible_timeout
在完成ceph_client的初始化动作后,下一步是打开会话:
linux/net/ceph/ceph_common.c:
int ceph_open_session(struct ceph_client *client)
{
...
ret = __ceph_open_session(client, started);
...
return ret;
}
/*
* mount: join the ceph cluster, and open root directory.
*/
int __ceph_open_session(struct ceph_client *client, unsigned long started)
{
int err;
/*timeout表示打开会话的超时时间,默认为60秒*/
unsigned long timeout = client->options->mount_timeout * HZ;
/*ceph_client内部是通过mon_client来打开会话,如果mon_client成功打开会话,
它会成功获得rados集群的mon_map(描述所有monitors信息)和osd_map(描述所有的osd信息)*/
/* open session, and wait for mon and osd maps */
err = ceph_monc_open_session(&client->monc);
if (err < 0)
return err;
while (!have_mon_and_osd_map(client)) { /*如果没有获得mon_map和osd_map,则等待直到超时*/
err = -EIO;
if (timeout && time_after_eq(jiffies, started + timeout)) /*超时退出*/
return err;
/* wait */
dout("mount waiting for mon_map\n");
/*下面,当前进程(rbd工具)将进入睡眠状态,直到内核接收到mon_map和osd_map时被重新唤醒,
或者出现认证错时也将被唤醒*/
err = wait_event_interruptible_timeout(client->auth_wq,
have_mon_and_osd_map(client) || (client->auth_err < 0),
timeout);
if (err == -EINTR || err == -ERESTARTSYS)
return err;
if (client->auth_err < 0)
return client->auth_err;
}
return 0;
}
linux/net/ceph/mon_client.c:
int ceph_monc_open_session(struct ceph_mon_client *monc)
{
mutex_lock(&monc->mutex);
__open_session(monc);
__schedule_delayed(monc);
mutex_unlock(&monc->mutex);
return 0;
}
/*
* Open a session with a (new) monitor.
*/
static int __open_session(struct ceph_mon_client *monc)
{
char r;
int ret;
if (monc->cur_mon < 0) {/*初始时cur_mon为-1,表示没有和任何monitor建立连接*/
/*通过随机数r,从初始化时生成的mon_map中随机选一个进行会话连接的monitor*/
get_random_bytes(&r, 1);
monc->cur_mon = r % monc->monmap->num_mon;
monc->sub_sent = 0;
monc->sub_renew_after = jiffies; /* i.e., expired */
monc->want_next_osdmap = !!monc->want_next_osdmap;
/*与选定的monitor建立网络连接,这里使用的messenger模块提供的接口*/
ceph_con_open(&monc->con,
CEPH_ENTITY_TYPE_MON, monc->cur_mon,
&monc->monmap->mon_inst[monc->cur_mon].addr);
/*初始化发送给monitor的首个hello消息*/
/* initiatiate authentication handshake */
ret = ceph_auth_build_hello(monc->auth,
monc->m_auth->front.iov_base,
monc->m_auth->front_alloc_len);
/*这里通过messenger模块的ceph_con_send接口将消息发送给monitor*/
__send_prepared_auth_request(monc, ret);
} else {
dout("open_session mon%d already open\n", monc->cur_mon);
}
return 0;
}
2.1.3. messenger模块使用方法小结
通过前文对mon_client的分析,我们来总结一下mon_client是如何使用底层的messenger模块的:
- (1) 通过ceph_messenger_init在ceph_client中初始化一个messenger对象,定义全局网络通信信息;该对象被mon_client和osd_client共享;
- (2) ceph_con_init(&monc->con, monc, &mon_con_ops, &monc->client->msgr),网络连接对象初始化,并指明该连接收到消息时的回调处理函数(消息将在内核工作队列上下文被处理);
- (3) ceph_con_open打开与选定monitor的网络连接;并拉起一个与当前连接关联的工作任务(connection worker),该任务负责该连接上网络消息的收发;
- (4) 发送消息时,先使用ceph_msg_new进行消息的内存分配,再填入消息内容,然后使用ceph_con_send进行消息发送;ceph_con_send会唤醒工作任务执行消息发送;
- (5) 接收消息时,内核网络协议栈在收到网卡消息后,会通过ceph注册的回调唤醒对应的connection worker进行收包,并调用初始化时绑定的消息处理回调函数;
- (6) mon_client关闭会话时使用ceph_con_close关闭连接;
2.1.4. 打开会话时客户端与monitor的交互(消息处理回调mon_con_ops分析)
目前monitor对我们来说还是一个黑盒,因此无法分析其内部是如何处理客户端发送的hello消息的。那么我们如何才能获知客户端是如何与monitor进行交互的?这里我们可以打开内核动态日志开关(代码中有很多dout语句),并通过分析日志来获知整个交互过程。通过打开libceph的messenger模块日志,我们可以得到如下图所示的消息交互过程:

从上图可见,TCP连接建立后的前几次消息交互主要是messenger模块对连接进行初始化,我们在将在深入分析messenger模块时分析。ceph connection初始化完成后,客户端首先便是向monitor发送Auth(hello)认证消息,关于认证的实现细节我们这里暂不深入分析,通过日志可知,整个认证会有三次Auth消息的交互:第一次Auth_reply返回前,monitor会向客户端返回monmap;第三次Auth_reply返回后,表示认证成功。认证成功之后客户端会向monitor发送Subscribe订阅消息,表示关注osdmap的更新。由于是首次认证,monitor会向client返回初始的osdmap,后续只有在osdmap有更新时,monitor才回返回更新后的map。
下面我们打开mon_con_ops看看客户端收到各类消息的处理过程:
linux/net/ceph/mon_client.c:
static const struct ceph_connection_operations mon_con_ops = {
...
.dispatch = dispatch, /*收到monitor的消息时会调用该函数*/
...
};
/*
* handle incoming message
*/
static void dispatch(struct ceph_connection *con, struct ceph_msg *msg)
{
struct ceph_mon_client *monc = con->private;
int type = le16_to_cpu(msg->hdr.type);
if (!monc)
return;
/*这里针对不同消息进行不同处理*/
switch (type) {
case CEPH_MSG_AUTH_REPLY:
handle_auth_reply(monc, msg);
break;
case CEPH_MSG_MON_SUBSCRIBE_ACK:
handle_subscribe_ack(monc, msg);
break;
case CEPH_MSG_STATFS_REPLY:
handle_statfs_reply(monc, msg);
break;
case CEPH_MSG_POOLOP_REPLY:
handle_poolop_reply(monc, msg);
break;
case CEPH_MSG_MON_MAP:
ceph_monc_handle_map(monc, msg);
break;
case CEPH_MSG_OSD_MAP:
ceph_osdc_handle_map(&monc->client->osdc, msg);
break;
default:
/* can the chained handler handle it? */
if (monc->client->extra_mon_dispatch &&
monc->client->extra_mon_dispatch(monc->client, msg) == 0)
break;
pr_err("received unknown message type %d %s\n", type,
ceph_msg_type_name(type));
}
ceph_msg_put(msg);
}
/*处理monmap消息,接收最新的monitor信息*/
static void ceph_monc_handle_map(struct ceph_mon_client *monc, struct ceph_msg *msg)
{
struct ceph_client *client = monc->client;
struct ceph_monmap *monmap = NULL, *old = monc->monmap;
void *p, *end;
...
dout("handle_monmap\n");
p = msg->front.iov_base;
end = p + msg->front.iov_len;
/*从收到的消息中解析出monmap内容,它包含所有monitor节点的IP信息*/
monmap = ceph_monmap_decode(p, end);
...
/*更新monmap*/
client->monc.monmap = monmap;
kfree(old);
...
out_unlocked:
/*唤醒所有在auth_wq中等待的任务*/
wake_up_all(&client->auth_wq);
}
/*处理osdmap消息,整体思路和monmap类似;这里分了增量和全量两种模式;
osdmap中记录了所有osd的IP和状态信息*/
/*
* Process updated osd map.
*
* The message contains any number of incremental and full maps, normally
* indicating some sort of topology change in the cluster. Kick requests
* off to different OSDs as needed.
*/
void ceph_osdc_handle_map(struct ceph_osd_client *osdc, struct ceph_msg *msg)
{
...
}
static void handle_auth_reply(struct ceph_mon_client *monc, struct ceph_msg *msg)
{
int ret;
int was_auth = 0;
...
/*处理auth_reply消息*/
ret = ceph_handle_auth_reply(monc->auth, msg->front.iov_base,
msg->front.iov_len,
monc->m_auth->front.iov_base,
monc->m_auth->front_alloc_len);
if (ret < 0) {
/*如果认证出错,则唤醒等待任务并返回错误信息*/
monc->client->auth_err = ret;
wake_up_all(&monc->client->auth_wq);
} else if (ret > 0) {
/*继续发送认证请求,从日志分析共会发送三次*/
__send_prepared_auth_request(monc, ret);
} else if (!was_auth && ceph_auth_is_authenticated(monc->auth)) {
/*认证成功,发送针对osdmap的订阅消息*/
dout("authenticated, starting session\n");
monc->client->msgr.inst.name.type = CEPH_ENTITY_TYPE_CLIENT;
monc->client->msgr.inst.name.num =
cpu_to_le64(monc->auth->global_id);
__send_subscribe(monc);
__resend_generic_request(monc);
}
...
}
2.2. rbd_dev_image_probe
rbd_dev_image_probe[*]
|-rbd_dev_image_id
| \-rbd_obj_method_sync -> rbd.get_id
|-rbd_dev_header_name
\-rbd_dev_v2_header_info
|-rbd_dev_v2_image_size
| \-rbd_obj_method_sync -> rbd.get_size
\-rbd_dev_v2_header_onetime
|-rbd_dev_v2_object_prefix
| \-rbd_obj_method_sync -> rbd.get_object_prefix
\-rbd_dev_v2_features
\-rbd_obj_method_sync -> rbd.get_features
通过前文的分析我们可知,当monitor返回monmap和osdmap后,rbd进程将继续往下执行到rbd_dev_image_probe,这里将从存放对象的OSD中获取与当前RBD设备相关的信息:
linux/drivers/block/rbd.c:
/*rbd_dev已分配内存空间,mapping为true*/
static int rbd_dev_image_probe(struct rbd_device *rbd_dev, bool mapping)
{
int ret;
int tmp;
/*从rados OSD池中获取当前RBD设备的image id,即对象"rbd_id.[RBD设备名称]"的内容*/
ret = rbd_dev_image_id(rbd_dev);
...
/*构造当前RBD设备元数据对象的名称,即"rbd_header.[image id]"*/
ret = rbd_dev_header_name(rbd_dev);
...
if (mapping) {
ret = rbd_dev_header_watch_sync(rbd_dev, true);
...
}
if (rbd_dev->image_format == 1)
ret = rbd_dev_v1_header_info(rbd_dev);
else
/*从rados OSD池中获取当前RBD设备元数据对象的omap信息*/
ret = rbd_dev_v2_header_info(rbd_dev);
...
return 0;
...
}
2.2.1. rbd_dev_image_probe -> rbd_dev_image_id
rbd_dev_image_probe
|-rbd_dev_image_id[*]
| \-rbd_obj_method_sync -> rbd.get_id
|-rbd_dev_header_name
\-rbd_dev_v2_header_info
|-rbd_dev_v2_image_size
| \-rbd_obj_method_sync -> rbd.get_size
\-rbd_dev_v2_header_onetime
|-rbd_dev_v2_object_prefix
| \-rbd_obj_method_sync -> rbd.get_object_prefix
\-rbd_dev_v2_features
\-rbd_obj_method_sync -> rbd.get_features
linux/drivers/block/rbd.c:
static int rbd_dev_image_id(struct rbd_device *rbd_dev)
{
int ret;
size_t size;
char *object_name;
void *response;
char *image_id;
...
/*对象名称为RBD_ID_PREFIX("rbd_id.")+image_name*/
size = sizeof (RBD_ID_PREFIX) + strlen(rbd_dev->spec->image_name);
object_name = kmalloc(size, GFP_NOIO);
...
/*返回的对象内容是一个经过编码的字符串,前四个字节代表后续内容的字节长度*/
size = sizeof (__le32) + RBD_IMAGE_ID_LEN_MAX;
response = kzalloc(size, GFP_NOIO);
...
/*调用rbd同步对象调用(call)接口(以面向对象class.method的方式来访问存储,即对象接口),这里本质就是获取"rbd_id.RBD名称"对象的内容:
(1)rbd_device为rbd_dev,即当前RBD设备;
(2)接口访问对象名称为object_name,即"rbd_id.RBD名称";
(3)接口访问类(class)名称为"rbd";
(4)接口访问方法(method)名称为"get_id";
(5)接口访问输入参数为空;
(6)接口访问输入参数长度为0;
(7)接口访问输出结果保存内存位置为response;
(8)接口访问输出结果保存内存最大长度为64。*/
ret = rbd_obj_method_sync(rbd_dev, object_name,
"rbd", "get_id", NULL, 0,
response, RBD_IMAGE_ID_LEN_MAX);
if (ret == -ENOENT) {
...
} else if (ret > sizeof (__le32)) {
void *p = response;
/*从返回结果中解析出对象内容,即image_id*/
image_id = ceph_extract_encoded_string(&p, p + ret, NULL, GFP_NOIO);
ret = IS_ERR(image_id) ? PTR_ERR(image_id) : 0;
if (!ret)
rbd_dev->image_format = 2;
} else {
ret = -EINVAL;
}
if (!ret) {
rbd_dev->spec->image_id = image_id;
dout("image_id is %s\n", image_id);
}
...
return ret;
}
2.2.2. rbd_dev_image_probe -> rbd_dev_header_name
rbd_dev_image_probe
|-rbd_dev_image_id
| \-rbd_obj_method_sync -> rbd.get_id
|-rbd_dev_header_name[*]
\-rbd_dev_v2_header_info
|-rbd_dev_v2_image_size
| \-rbd_obj_method_sync -> rbd.get_size
\-rbd_dev_v2_header_onetime
|-rbd_dev_v2_object_prefix
| \-rbd_obj_method_sync -> rbd.get_object_prefix
\-rbd_dev_v2_features
\-rbd_obj_method_sync -> rbd.get_features
linux/drivers/block/rbd.c:
static int rbd_dev_header_name(struct rbd_device *rbd_dev)
{
struct rbd_spec *spec = rbd_dev->spec;
size_t size;
...
/*header_name表示RBD设备对应头部对象(其omap保存了RBD设备元数据信息)名称
即"rbd_header."+image_id*/
size = sizeof (RBD_HEADER_PREFIX) + strlen(spec->image_id);
rbd_dev->header_name = kmalloc(size, GFP_KERNEL);
...
sprintf(rbd_dev->header_name, "%s%s", RBD_HEADER_PREFIX, spec->image_id);
return 0;
}
2.2.3. rbd_dev_image_probe -> rbd_dev_v2_header_info
rbd_dev_image_probe
|-rbd_dev_image_id
| \-rbd_obj_method_sync -> rbd.get_id
|-rbd_dev_header_name
\-rbd_dev_v2_header_info[*]
|-rbd_dev_v2_image_size
| \-rbd_obj_method_sync -> rbd.get_size
\-rbd_dev_v2_header_onetime
|-rbd_dev_v2_object_prefix
| \-rbd_obj_method_sync -> rbd.get_object_prefix
\-rbd_dev_v2_features
\-rbd_obj_method_sync -> rbd.get_features
linux/drivers/block/rbd.c:
/*这里我们忽略与快照特性(snapshot)相关代码*/
static int rbd_dev_v2_header_info(struct rbd_device *rbd_dev)
{
bool first_time = rbd_dev->header.object_prefix == NULL;
int ret;
down_write(&rbd_dev->header_rwsem);
ret = rbd_dev_v2_image_size(rbd_dev);
...
if (first_time) {
ret = rbd_dev_v2_header_onetime(rbd_dev);
...
}
...
up_write(&rbd_dev->header_rwsem);
return ret;
}
static int rbd_dev_v2_image_size(struct rbd_device *rbd_dev)
{
return _rbd_dev_v2_snap_size(rbd_dev, CEPH_NOSNAP,
&rbd_dev->header.obj_order,
&rbd_dev->header.image_size);
}
static int _rbd_dev_v2_snap_size(struct rbd_device *rbd_dev, u64 snap_id,
u8 *order, u64 *snap_size)
{
__le64 snapid = cpu_to_le64(snap_id);
int ret;
struct {
u8 order;
__le64 size;
} __attribute__ ((packed)) size_buf = { 0 };
/*调用rbd同步对象访问接口,这里本质就是获取“rbd_header.image_id"对象中omap对应key的内容:
(1)rbd_device为rbd_dev,即当前RBD设备;
(2)接口访问对象名称为“rbd_header.image_id";
(3)接口访问类(class)名称为"rbd";
(4)接口访问方法(method)名称为"get_size",对应omap中的key为"size";
(5)接口访问输入参数为snapid;
(6)接口访问输入参数长度为snapid的字节长度;
(7)接口访问输出结果保存内存位置为size_buf;
(8)接口访问输出结果保存内存最大长度为size_buf空间大小。*/
ret = rbd_obj_method_sync(rbd_dev, rbd_dev->header_name,
"rbd", "get_size",
&snapid, sizeof (snapid),
&size_buf, sizeof (size_buf));
dout("%s: rbd_obj_method_sync returned %d\n", __func__, ret);
...
if (order) {
*order = size_buf.order;
dout(" order %u", (unsigned int)*order);
}
*snap_size = le64_to_cpu(size_buf.size);
...
return 0;
}
static int rbd_dev_v2_header_onetime(struct rbd_device *rbd_dev)
{
int ret;
/*通过rbd_obj_method_sync获取头部对象omap中的"object_prefix"key的内容*/
ret = rbd_dev_v2_object_prefix(rbd_dev);
if (ret)
goto out_err;
/*通过rbd_obj_method_sync获取头部对象omap中的"features"key的内容*/
ret = rbd_dev_v2_features(rbd_dev);
if (ret)
goto out_err;
...
return ret;
}
2.2.4. rbd_obj_method_sync
通过前文分析,我们看到多个子函数中均使用了rbd_obj_method_sync函数来访问rados对象内容。该函数是对远程rados对象的同步调用接口,是对底层libceph接口(osd_client)的封装:
linux/drivers/block/rbd.c:
/*
* Synchronous osd object method call. Returns the number of bytes
* returned in the outbound buffer, or a negative error code.
*/
/*osd对象的同步方法调用,返回结果在inbound中。注:上文的注释有问题*/
static int rbd_obj_method_sync(struct rbd_device *rbd_dev, /*当前RBD设备*/
const char *object_name, /*访问对象名称*/
const char *class_name, /*访问类名称*/
const char *method_name, /*访问方法名称*/
const void *outbound, /*输入参数内存位置*/
size_t outbound_size, /*输入参数大小*/
void *inbound, /*返回结果内存位置*/
size_t inbound_size) /*返回结果大小*/
{
struct ceph_osd_client *osdc = &rbd_dev->rbd_client->client->osdc; /*osd_client是底层libceph接口对象*/
struct rbd_obj_request *obj_request;
struct page **pages;
u32 page_count;
int ret;
/*
* Method calls are ultimately read operations. The result
* should placed into the inbound buffer provided. They
* also supply outbound data--parameters for the object
* method. Currently if this is present it will be a
* snapshot id.
*/
/*上面这段注释的意思是说针对对象的method call最终其实是对象的读操作。
outbound表示method输入参数,当前只支持snapid;
inbound表示返回结果。*/
/*为返回结果inbound分配新的内存页, 为何要重新分配内存?*/
page_count = (u32)calc_pages_for(0, inbound_size);
pages = ceph_alloc_page_vector(page_count, GFP_KERNEL);
if (IS_ERR(pages))
return PTR_ERR(pages);
ret = -ENOMEM;
/*创建新的rbd_obj_request对象并初始化*/
obj_request = rbd_obj_request_create(object_name, 0, inbound_size, OBJ_REQUEST_PAGES);
if (!obj_request)
goto out;
obj_request->pages = pages;
obj_request->page_count = page_count;
/*创建rbd_obj_request在libceph对应的osd_request对象*/
obj_request->osd_req = rbd_osd_req_create(rbd_dev, false, obj_request);
if (!obj_request->osd_req)
goto out;
/*初始化osd_request中的op对象,它的类型为CEPH_OSD_OP_CALL,表示调用远端OSD中对象的方法*/
osd_req_op_cls_init(obj_request->osd_req, 0, CEPH_OSD_OP_CALL, class_name, method_name);
if (outbound_size) {
/*如果存在输入参数outbound,则为其分配新的内存页并复制其内容*/
struct ceph_pagelist *pagelist;
pagelist = kmalloc(sizeof (*pagelist), GFP_NOFS);
if (!pagelist)
goto out;
ceph_pagelist_init(pagelist);
ceph_pagelist_append(pagelist, outbound, outbound_size); /*将outbound中内容复制到pagelist*/
osd_req_op_cls_request_data_pagelist(obj_request->osd_req, 0,pagelist); /*将pagelist作为op的输入参数(request_data)*/
}
osd_req_op_cls_response_data_pages(obj_request->osd_req, 0,
obj_request->pages, inbound_size, 0, false, false);/*将obj_request->pages作为op的输出结果(response_data)*/
rbd_osd_req_format_read(obj_request);
/*将rbd_object_request对象提交给底层libceph发送给远端osd节点*/
ret = rbd_obj_request_submit(osdc, obj_request);
if (ret)
goto out;
/*等待远端osd节点返回响应*/
ret = rbd_obj_request_wait(obj_request);
if (ret)
goto out;
/*远端osd节点返回响应后,result中保存返回结果*/
ret = obj_request->result;
if (ret < 0)
goto out;
rbd_assert(obj_request->xferred < (u64)INT_MAX);
ret = (int)obj_request->xferred;
/*根据远端osd返回的数据量xferred,将数据拷贝到inbound中*/
ceph_copy_from_page_vector(pages, inbound, 0, obj_request->xferred);
out:
if (obj_request)
rbd_obj_request_put(obj_request);
else
ceph_release_page_vector(pages, page_count);
return ret;
}
2.3. rbd_dev_device_setup
基于之前获取的信息,我们可以通过内核块层提供的相关接口创建一个新的RBD块设备对象供应用使用:
linux/drivers/block/rbd.c:
static int rbd_dev_device_setup(struct rbd_device *rbd_dev)
{
int ret;
/*首先根据全局变量rbd_dev_id_max生成一个新的最大id号*/
/* generate unique id: find highest unique id, add one */
rbd_dev_id_get(rbd_dev);
/*根据id号生成设备名称*/
/* Fill in the device name, now that we have its id. */
BUILD_BUG_ON(DEV_NAME_LEN < sizeof (RBD_DRV_NAME) + MAX_INT_FORMAT_WIDTH);
sprintf(rbd_dev->name, "%s%d", RBD_DRV_NAME, rbd_dev->dev_id);
/* Get our block major device number. */
/*通过块层接口register_blkdev注册一个新的块设备*/
ret = register_blkdev(0, rbd_dev->name);
if (ret < 0)
goto err_out_id;
rbd_dev->major = ret;
/* Set up the blkdev mapping. */
/*调用块层接口初始化gendisk对象,绑定其IO处理函数为rbd_request_fn(我们将以此为入口来分析IO流程)*/
ret = rbd_init_disk(rbd_dev);
if (ret)
goto err_out_blkdev;
/*快照相关,暂不关心*/
ret = rbd_dev_mapping_set(rbd_dev);
if (ret)
goto err_out_disk;
/*设备容量*/
set_capacity(rbd_dev->disk, rbd_dev->mapping.size / SECTOR_SIZE);
/*在sys目录下添加设备*/
ret = rbd_bus_add_dev(rbd_dev);
if (ret)
goto err_out_mapping;
/* Everything's ready. Announce the disk to the world. */
/*通过add_disk接口在系统中呈现一个新的块设备*/
set_bit(RBD_DEV_FLAG_EXISTS, &rbd_dev->flags);
add_disk(rbd_dev->disk);
pr_info("%s: added with size 0x%llx\n", rbd_dev->disk->disk_name,
(unsigned long long) rbd_dev->mapping.size);
return ret;
err_out_mapping:
rbd_dev_mapping_clear(rbd_dev);
err_out_disk:
rbd_free_disk(rbd_dev);
err_out_blkdev:
unregister_blkdev(rbd_dev->major, rbd_dev->name);
err_out_id:
rbd_dev_id_put(rbd_dev);
rbd_dev_mapping_clear(rbd_dev);
return ret;
}