
本节将讨论内存压缩,计算子系统相关内容目录点此进入。
什么是内存压缩?为什么需要它?
内存压缩(memory compaction)是指把应用程序正在使用的物理页内容迁移(migrate)到其它物理页中,以释放原有物理页,从而方便空闲页的合并以形成大段连续空闲内存,有效避免内存碎片的产生。
前文介绍优化型伙伴算法时,我们已经看到空闲内存被分成不可移动、可回收、可移动几个类别,应用程序从可移动类别中获取内存页。连续的内存分配和释放如果产生碎片无法满足当前内存分配请求时,内核进入慢速分配流程触发内存压缩,进行碎片整理,从而最大限度满足分配需求。
如何实现?
从整体流程上看,内存分配函数alloc_pages在快速流程get_page_from_freelist无法满足时,会进入慢速流程__alloc_pages_slowpath。慢速流程中进行一系列尝试后如果仍然无法满足分配需求,则进入compact_zone内存压缩流程。
内存压缩是通过迁移实现,迁移就涉及源端和目的端,那么内存压缩过程所要考虑的第一个问题就是源端页从哪来?目的端页又从哪来?Linux内核采用的策略是把低地址的页移动到高地址,从而在低地址端形成大段连续内存。因此内核从低往高扫描内存区(zone),收集需要迁移的源端内存页;另一方面从高往低扫描,获取迁移目的端的空闲页。迁移源端页的收集在isolate_migratepage函数中实现,目的端页的收集在isolate_freepages函数中实现,有兴趣的读者可以深入进一步分析。
迁移源端和目的端确认后,下面要考虑的就是迁移动作该如何完成。粗略来说,需要将源端页内容拷贝到目的页、将文件映射关系中的源端页替换成目的端页、解除源端页在页表中的映射并重新映射目的页。
下图展示了使用中的物理页的映射关系:进程的虚拟地址段(vma)通过mmap被映射到文件段;文件内容读取到物理内存后以缓存页方式被组织成文件映射树;页表将虚拟地址映射到文件缓存页,供MMU使用实现地址转换。

基于上图,我们看看迁移过程:总体分两步,首先解映射源端页;其次是将映射树的源端页替换成目的页,包括内存页内容的拷贝。
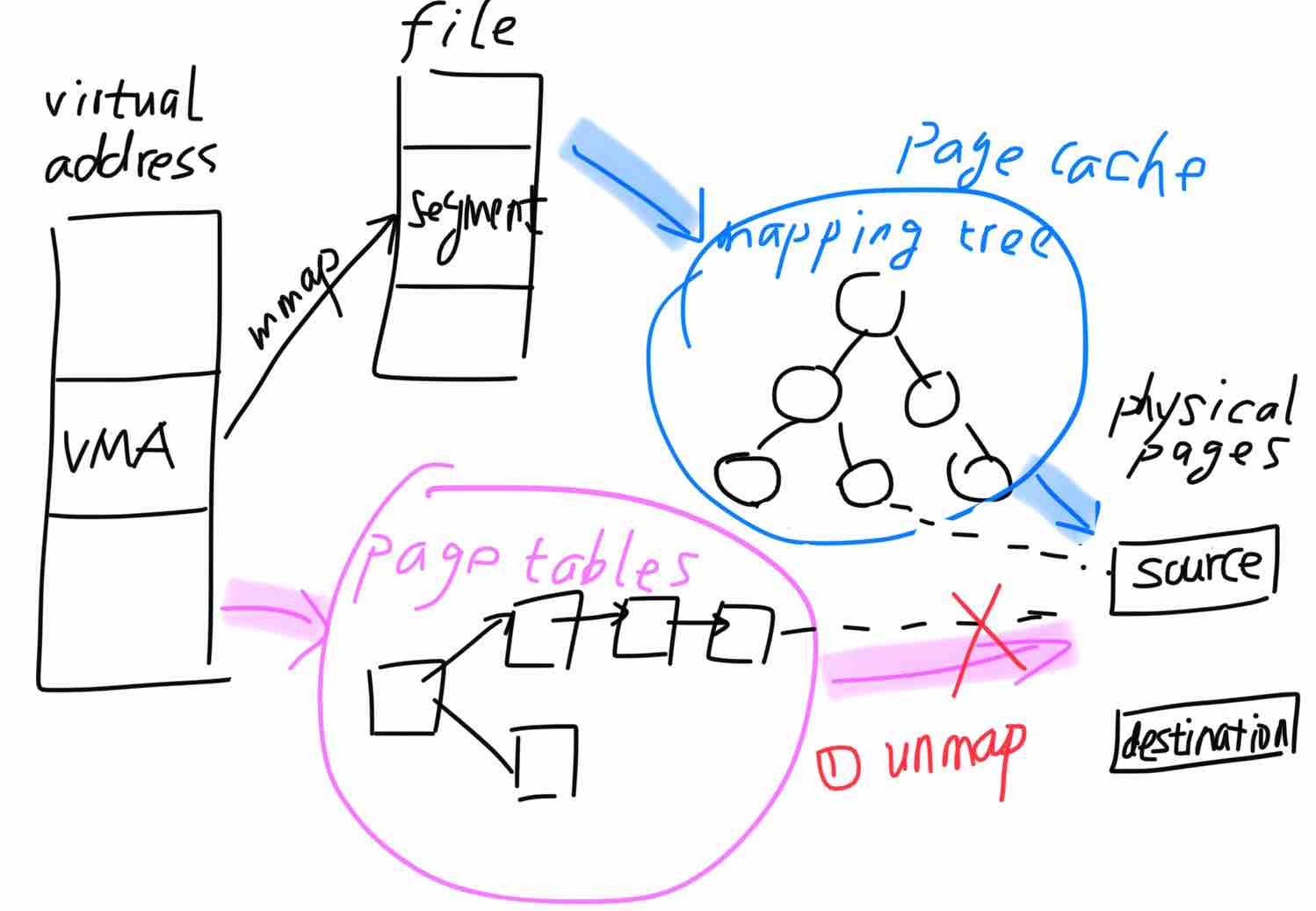
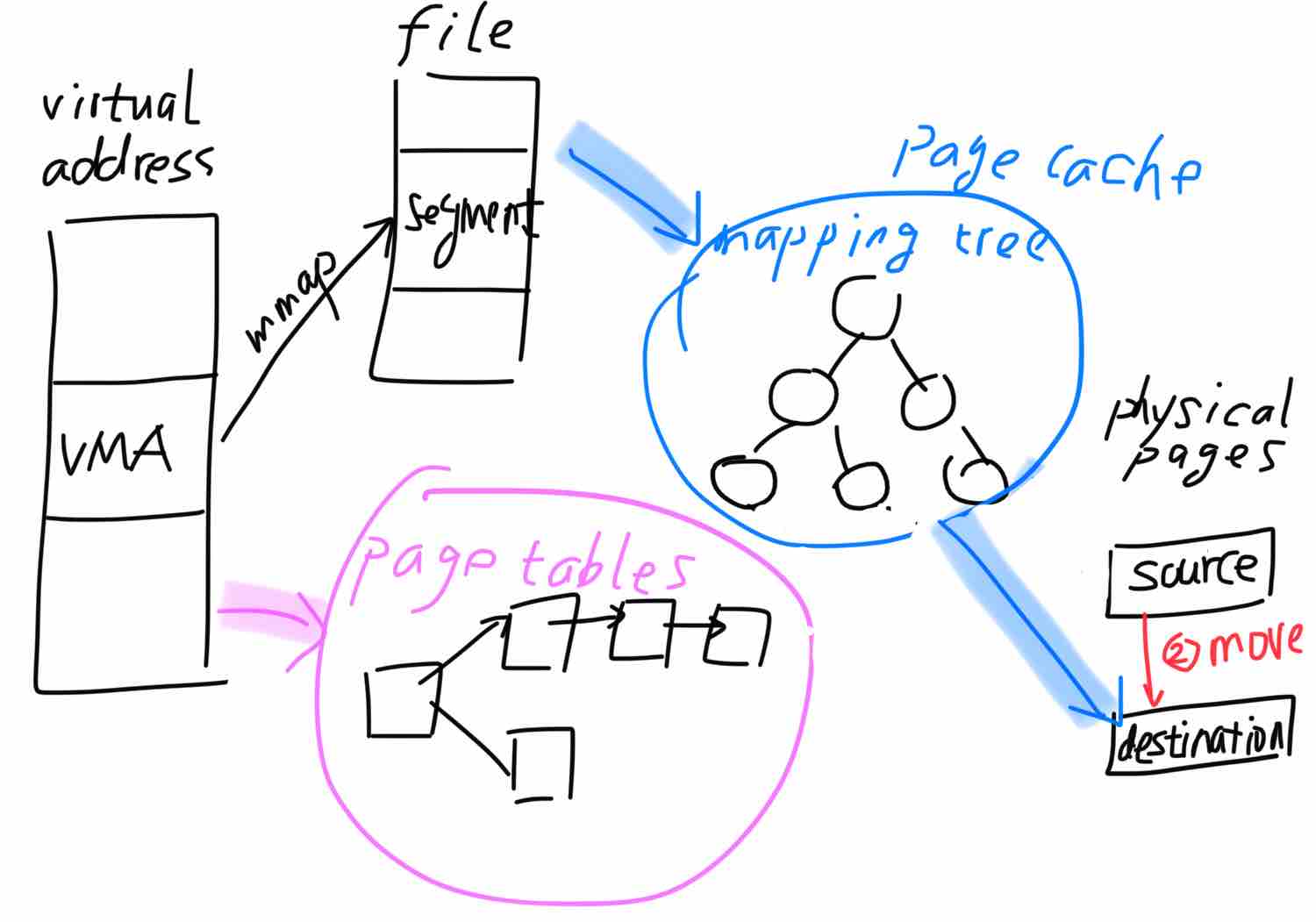
有的读者可能会问,怎么最后没有重新将虚拟地址映射到目的页呢?内核采用的是lazy的方式,当进程访问缺页时会完成重新映射。 详细代码在migrate_pages中:
linux/mm/migrate.c:
/*
* migrate_pages - migrate the pages specified in a list, to the free pages
* supplied as the target for the page migration
*
* @from: The list of pages to be migrated.
* @get_new_page: The function used to allocate free pages to be used
* as the target of the page migration.
* @private: Private data to be passed on to get_new_page()
* @mode: The migration mode that specifies the constraints for
* page migration, if any.
* @reason: The reason for page migration.
*
* The function returns after 10 attempts or if no pages are movable any more
* because the list has become empty or no retryable pages exist any more.
* The caller should call putback_lru_pages() to return pages to the LRU
* or free list only if ret != 0.
*
* Returns the number of pages that were not migrated, or an error code.
*/
int migrate_pages(struct list_head *from, new_page_t get_new_page,
unsigned long private, enum migrate_mode mode, int reason)
{
int retry = 1;
int nr_failed = 0;
int nr_succeeded = 0;
int pass = 0;
struct page *page;
struct page *page2;
int swapwrite = current->flags & PF_SWAPWRITE;
int rc;
if (!swapwrite)
current->flags |= PF_SWAPWRITE;
for(pass = 0; pass < 10 && retry; pass++) {
retry = 0;
list_for_each_entry_safe(page, page2, from, lru) {
cond_resched();
/*解映射页表并移动内存页,内部将调用__unmap_and_move*/
rc = unmap_and_move(get_new_page, private, page, pass > 2, mode);
switch(rc) {
case -ENOMEM:
goto out;
case -EAGAIN:
retry++;
break;
case MIGRATEPAGE_SUCCESS:
nr_succeeded++;
break;
default:
/* Permanent failure */
nr_failed++;
break;
}
}
}
rc = nr_failed + retry;
out:
if (nr_succeeded)
count_vm_events(PGMIGRATE_SUCCESS, nr_succeeded);
if (nr_failed)
count_vm_events(PGMIGRATE_FAIL, nr_failed);
trace_mm_migrate_pages(nr_succeeded, nr_failed, mode, reason);
if (!swapwrite)
current->flags &= ~PF_SWAPWRITE;
return rc;
}
static int __unmap_and_move(struct page *page, struct page *newpage,
int force, enum migrate_mode mode)
{
int rc = -EAGAIN;
int remap_swapcache = 1;
struct mem_cgroup *mem;
struct anon_vma *anon_vma = NULL;
/*锁定迁移源端页*/
if (!trylock_page(page)) {
...
}
if (PageWriteback(page)) {
/*跳过或等待writeback页回刷完成*/
...
}
...
/* Establish migration ptes or remove ptes */
try_to_unmap(page, TTU_MIGRATION|TTU_IGNORE_MLOCK|TTU_IGNORE_ACCESS);
skip_unmap:
if (!page_mapped(page))
rc = move_to_new_page(newpage, page, remap_swapcache, mode);
...
out:
return rc;
}
static int move_to_new_page(struct page *newpage, struct page *page,
int remap_swapcache, enum migrate_mode mode)
{
struct address_space *mapping;
int rc;
/*
* Block others from accessing the page when we get around to
* establishing additional references. We are the only one
* holding a reference to the new page at this point.
*/
if (!trylock_page(newpage))
BUG();
/* Prepare mapping for the new page.*/
newpage->index = page->index;
newpage->mapping = page->mapping;
if (PageSwapBacked(page))
SetPageSwapBacked(newpage);
mapping = page_mapping(page);
/*调用底层文件系统接口实现页迁移*/
if (!mapping)
rc = migrate_page(mapping, newpage, page, mode);
else if (mapping->a_ops->migratepage)
/*
* Most pages have a mapping and most filesystems provide a
* migratepage callback. Anonymous pages are part of swap
* space which also has its own migratepage callback. This
* is the most common path for page migration.
*/
rc = mapping->a_ops->migratepage(mapping, newpage, page, mode);
else
rc = fallback_migrate_page(mapping, newpage, page, mode);
if (rc != MIGRATEPAGE_SUCCESS) {
newpage->mapping = NULL;
} else {
if (remap_swapcache)
remove_migration_ptes(page, newpage);
page->mapping = NULL;
}
unlock_page(newpage);
return rc;
}
至此,慢速分配中的核心的内存压缩流程已分析完成,更底层的细节涉及具体文件系统实现,大家可以继续深入分析。
转载请注明:吴斌的博客 » 【计算子系统】内存管理之五:内存压缩