
从计算机系统内部看,中断无时无刻不在,这篇博文就和大家一起探讨中断的原理,并以x86_64平台上的linux 3.10内核为例来分析底层实现细节。
什么是中断?
中断是一个系统过程,是计算系统中外部设备向CPU(或CPU之间)通知事件发生的一种机制。这种说法也许有些偏底层,可以从上层更直观的角度来理解:想象你正面对你的个人电脑,当你按下一个键盘按键时,你就触发了一个中断,随后屏幕上会出现你期望的字母;或者当你移动鼠标时,你也会触会一个中断,随后光标会随鼠标的移动而移动。严格意义上说,中断只是一个系统过程(系统调用过程如果抛开其核心处理函数的执行,也是一个系统过程),是系统的一个部分,而不是一个完整系统,因为它不具备完整系统所应有的功能、性能、可靠性、可扩展性、安全性、兼容性、可维护性等各方面的属性。比如,通过按动键盘,你以中断的方式向计算系统发送命令,但真正执行命令并返回结果的是计算机系统而不是按键动作本身。
为什么需要中断?
计算机是个“死脑筋”,从打开电源键开始,就算你不向她发送任何指令,她也会按设定的程序开始忙禄,大多时候都在执行一个叫做IDEL的无聊程序。如何让她听命于你呢?两种方法,要么让她随时可被打断,去做你想让她做的事,随后再去干原来被打断的事;要么让她不停地一直问你想让她做什么,其它的事啥也不干,这样你一发话,她可以立刻响应你的命令。第一种方式,便是中断(interrupt),第二种方式叫轮询(polling)。在大多数场景下,中断都是一种更为高效的(从完成任务数来看)通知方式,因为计算机干了更多有意义的事,而不是一直在“傻问”;轮询时,如果你想让计算机干得活不是很多,那么计算机大多数问询得到结果都是“谢谢,我不需要你做什么”,这就白白浪费了她的宝贵精力,但是每次你想让计算机做事时,她总是先主动地询问你,之后便立刻进入工作状态了,这比下达命令之后才慢吞吞开始行动的中断方式更为高效(从任务响应时间来看)。因此中断和轮询各有优点,各有各的适用场景:中断适用大多数设备通知场景,而在处理时延敏感场景下(如高性能网络转发),轮询表现得更好。
如何实现中断?
下面我们深入系统内部,更细致地理解中断过程。前期的博文介绍过intel i440fx体系的基本组成,这里我们做些简化,只看和中断过程相关的几个部分,并按中断发生后的时序对中断过程作一个概括性的描述:
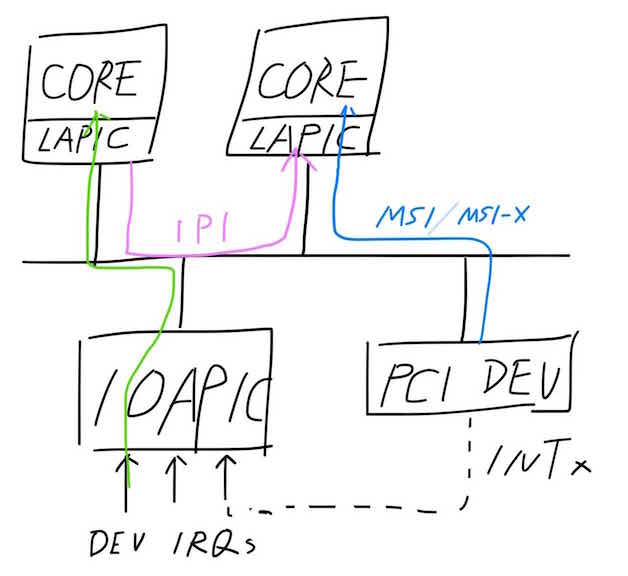
- 首先,我们可以看到在南桥芯片上集成了一个称为IOAPIC的部件,它共有24根中断引脚可以接收来自外部设备(如键盘、鼠标)的中断请求;当外设触发中断请求后,IOAPIC芯片会根据设备驱动初始化时设定的内容(一个内存地址Address和一个数据Data)向总线发送中断信息(将Data值写入Address地址代表的内存),如图中绿色线条所示,直观地理解,这个Address指明了接收本次中断的具体CPU,而Data代表中断向量号(粗略地讲,可以认为这是不同中断相互区别的一个整数值,0~255)。
- 其次,对于PCI设备而言,有两种中断触发方式:一种是通过intx中断引脚触发(最终通过IOAPIC发送中断信号,如图中虚线所示);另一种是MSI/MSI-X方式(Message Signal Interrupt),PCI设备通过驱动初始化时设定的内容直接向总线发送中断,如图中蓝线所示,其发送原理类似IOAPIC,由于外部设备中断过程并非本文讨论的重点,有兴趣的同学可以查阅PCI规范中相关内容来获得更深入的理解。
- 此外,CPU之间可以通过写ICR寄存器发送IPI(Inter Processors Interrupt)中断来进行核间通信,如图中粉色线条所示。
- 最后,每个CPU逻辑核都有一个称为LAPIC的子部件,它负责接收总线上的中断信息,当确认是发送给本地逻辑核时,便会引发本地CPU的中断过程:CPU会对保存当前正在执行任务的状态信息,之后会根据中断信息找到具体的中断处理逻辑函数;在完成中断处理函数后,CPU便会恢复先前保存的任务状态,继续处理原先的作务。
CPU如何处理中断?
介绍完系统内部整体的中断过程后,我们把焦点放到CPU上,更深入地从代码级别看看它是如何处理中断的。
1、硬件自动完成动作
x86_64 CPU在中断发生时会执行一系列硬件动作,完成执行上下文的切换,这些都是硬件自动完成的,不受软件控制,如下图所示:

图中上半部分表示中断发生前寄存器状态(这里以用户态上下文状态举例):
- CS(代码段寄存器)和rip(指令指针寄存器)指向了当前正在执行的用户态指令的位置(绿色线条所示);
- SS(堆栈段寄存器)和rsp(栈指针寄存器)指向了当前用户态堆栈的栈项位置;
- rflags(标志寄存器)中的IF位为1,表示允许中断发生;
- TR(Task Register)任务寄存器指向当前任务的任务状态段TSS(Task State Segment),其中的rsp0域指向了内核态栈顶位置(内核特权级为0);
- IDTR(Interrupt Descriptor Table Register)指向了全局中断描述符表(Interrupt Descriptor Table),表中共有256个中断描述符(Interrupt Descriptor),每个描述符指向一个中断处理函数入口,中断描述符在表中的索引(下标)称为中断向量(Interrupt Vector)。
中断发生后(只能发生在指令边界,不能打断单条指令的执行),寄存器状态将发生变化,如上图下半部分所示:
- 对于运行在用户态的程序,中断发生后需要切换到内核态执行中断处理函数,出于安全的考虑,堆栈也需要切换到内核态(注意,每个进程在内核态都有一个独立的栈空间,3.10内核中有16K大小,栈项指针保存在TSS);
- 切换到内核态栈后,CPU自动将用户态SS、rsp、rflags、CS、rip压入栈中(从上到下,栈顶在下,栈底在上);
- CPU根据中断向量,取出中断描述符表中对应的中断描述符,将CS:rip指向中断描述符中的函数入口地址;
- 对于类型为Interrupt Gate的中断描述符,rflags中的IF标置位将被清零,表示CPU此时开始不响应外部中断。
细心的同学可能会问如果程序正好在执行系统调用进入内核态,那中断的硬件过程是怎样的?除了不用进行栈切换外,其它的过程和上面的一样,因为系统调用已经完成了栈切换的动作。
2、中断描述符表
硬件自动完成动作的最后是根据中断描述表中的内容找到中断处理函数入口,下面我们看看3.10内核里的中断描述符表的相关实现,其初始流程大致为start_kernel->init_IRQ->native_init_IRQ,其核心片断如下所示:
arch/x86/kernel/irqinit.c:
void __init native_init_IRQ(void)
{
int i;
...
/*
* Cover the whole vector space, no vector can escape
* us. (some of these will be overridden and become
* 'special' SMP interrupts)
*/
i = FIRST_EXTERNAL_VECTOR;
for_each_clear_bit_from(i, used_vectors, NR_VECTORS) {
/* IA32_SYSCALL_VECTOR could be used in trap_init already. */
set_intr_gate(i, interrupt[i - FIRST_EXTERNAL_VECTOR]);
}
...
}
FIRST_EXTERNAL_VECTOR为32,NR_VECTOR为256,开头的这段注释的意思是说这里会给从32到256的所有中断向量注册处理函数,从下面的代码看出处理函数在全局数组interrupt中。那么就有两个问题:为什么从32开始?为什么一开始就能把中断处理函数全部注册好,此时驱动程序都没初始化,具体的中断处理逻辑难道不是在驱动代码中实现的吗?第一个问题比较好回答,其实0~31的向量是intel预留给异常使用的,这是CPU用来处理内部问题的一种方式,如除零、缺页等等。第二个问题目前确实比较难回答,我们就带着这个问题看看interrupt数组的定义吧:
arch/x86/kernel/entry_64.S:
/*
* Build the entry stubs and pointer table with some assembler magic.
* We pack 7 stubs into a single 32-byte chunk, which will fit in a
* single cache line on all modern x86 implementations.
*/
.section .init.rodata,"a"
ENTRY(interrupt)
.section .entry.text
.p2align 5
.p2align CONFIG_X86_L1_CACHE_SHIFT
ENTRY(irq_entries_start)
vector=FIRST_EXTERNAL_VECTOR
.rept (NR_VECTORS-FIRST_EXTERNAL_VECTOR+6)/7
.balign 32
.rept 7
.if vector < NR_VECTORS
1: pushq_cfi $(~vector+0x80) /* Note: always in signed byte range */
.if ((vector-FIRST_EXTERNAL_VECTOR)%7) <> 6
jmp 2f
.endif
.previous
.quad 1b
.section .entry.text
vector=vector+1
.endif
.endr
2: jmp common_interrupt
.endr
END(irq_entries_start)
.previous
END(interrupt)
.previous
这段汇编代码确实比较晦涩,它把32到256的中断按7个一组划成一个个大组,每个大组的内存占用空间大小在32个字节内,这样这些组块可以被CPU缓存到内部缓存中,以加速对这些内存的访问,显然这是一个性能优化手段。每个大组内包含了7个中断的桩(stub)函数和每个中断的处理函数入口地址,其内存结构如下图所示:

每个中断处理函数的入口地址以XXX_表示,桩函数包含两条指令,一条push指令和一条jmp指令。前6个中断桩函数的jmp指令都会跳转到最后一个桩函数的jmp指令位置,而该指令最终跳转到common_interrupt位置处继续执行。在每个桩函数的最后(组内的最后一个桩函数是在jmp指令前)放置了当前处理函数的入口地址,最终这些地址会组成全局interrupt数组。
3、公共入口函数common_interrupt
从上节的介绍中可以看出,中断发生后,CPU会执行中断描述符表所指向的各个中断的桩函数(如上图中XXX_32表示32号向量所对应的中断处理函数入口),而所有桩函数在将中断向量压入栈后(会做符号化处理),最终会跳转到common_interrupt函数,这个函数就成了所有中断的公共入口:
arch/x86/kernel/entry_64.S:
/*
* Interrupt entry/exit.
*
* Interrupt entry points save only callee clobbered registers in fast path.
*
* Entry runs with interrupts off.
*/
/* 0(%rsp): ~(interrupt number) */
.macro interrupt func
/* reserve pt_regs for scratch regs and rbp */
subq $ORIG_RAX-RBP, %rsp
SAVE_ARGS_IRQ
call \func
.endm
/*
* Interrupt entry/exit should be protected against kprobes
*/
.pushsection .kprobes.text, "ax"
/*
* The interrupt stubs push (~vector+0x80) onto the stack and
* then jump to common_interrupt.
*/
.p2align CONFIG_X86_L1_CACHE_SHIFT
common_interrupt:
addq $-0x80,(%rsp) /* Adjust vector to [-256,-1] range */
interrupt do_IRQ
/* 0(%rsp): old_rsp-ARGOFFSET */
ret_from_intr:
...
这里的interrupt代表一个宏,而不是之前讨论的interrupt全局数组。common_interrupt的工作过程就是将栈顶的向量号转化成负数(-256,-1),然后通过SAVE_ARGS_IRQ宏保存必要的寄要器,最后调用C语言函数do_IRQ来处理中断。SAVE_ARGS_IRQ宏定义如下:
arch/x86/kernel/entry_64.S:
/* save partial stack frame */
.macro SAVE_ARGS_IRQ
cld
/* start from rbp in pt_regs and jump over */
movq_cfi rdi, (RDI-RBP)
movq_cfi rsi, (RSI-RBP)
movq_cfi rdx, (RDX-RBP)
movq_cfi rcx, (RCX-RBP)
movq_cfi rax, (RAX-RBP)
movq_cfi r8, (R8-RBP)
movq_cfi r9, (R9-RBP)
movq_cfi r10, (R10-RBP)
movq_cfi r11, (R11-RBP)
/* Save rbp so that we can unwind from get_irq_regs() */
movq_cfi rbp, 0
/* Save previous stack value */
movq %rsp, %rsi
leaq -RBP(%rsp),%rdi /* arg1 for handler */
testl $3, CS-RBP(%rsi)
je 1f
SWAPGS
/*
* irq_count is used to check if a CPU is already on an interrupt stack
* or not. While this is essentially redundant with preempt_count it is
* a little cheaper to use a separate counter in the PDA (short of
* moving irq_enter into assembly, which would be too much work)
*/
1: incl PER_CPU_VAR(irq_count)
cmovzq PER_CPU_VAR(irq_stack_ptr),%rsp
/* Store previous stack value */
pushq %rsi
TRACE_IRQS_OFF
.endm
arch/x86/include/asm/calling.h:
/*
* 64-bit system call stack frame layout defines and helpers,
* for assembly code:
*/
#define R15 0
#define R14 8
#define R13 16
#define R12 24
#define RBP 32
#define RBX 40
/* arguments: interrupts/non tracing syscalls only save up to here: */
#define R11 48
#define R10 56
#define R9 64
#define R8 72
#define RAX 80
#define RCX 88
#define RDX 96
#define RSI 104
#define RDI 112
#define ORIG_RAX 120 /* + error_code */
/* end of arguments */
/* cpu exception frame or undefined in case of fast syscall: */
#define RIP 128
#define CS 136
#define EFLAGS 144
#define RSP 152
#define SS 160
为什么只保存rdi~r11寄存器?这就涉及gcc编译方面的知识了,对于一个C函数来说,调用者如果在rdi~r11寄存器中保存了有用的信息,那调用者就需要在执行该C函数的调用前保存这些寄存器,因为C函数执行的过程中有可能会修改这些寄存器且不对这些寄存器做保存;而对于rbx,rbp,r12-r15这些寄存器,调用者如果在其中保存了有用的信息,在C函数调用返回后,这些寄存器的值不会发生改变,因为如果C函数内部会使用这些寄存器,它会保存旧的值并在函数返回前恢复这些寄存器旧有的值。
终于来到了C语言函数do_IRQ:
arch/x86/kernel/irq.c:
/*
* do_IRQ handles all normal device IRQ's (the special
* SMP cross-CPU interrupts have their own specific
* handlers).
*/
unsigned int __irq_entry do_IRQ(struct pt_regs *regs)
{
struct pt_regs *old_regs = set_irq_regs(regs);
/* high bit used in ret_from_ code */
unsigned vector = ~regs->orig_ax;
unsigned irq;
irq_enter();
exit_idle();
irq = __this_cpu_read(vector_irq[vector]);
if (!handle_irq(irq, regs)) {
...
}
irq_exit();
set_irq_regs(old_regs);
return 1;
}
上述函数的参数regs对应寄存器rdi(可以回顾下x86_64寄存器传参规则),它是在SAVE_ARGS_IRQ宏中赋值的,指向了栈顶保存的r15寄存器。我理解此时栈顶有可能并没有保存r15寄存器的值,就看do_IRQ函数汇编后需不需要使用r15,但是其实do_IRQ只需要通过regs找到偏移为orig_ax的值(保存了向量号)就行,并不会去访问regs->r15,所以并不影响程序的正确性。
- do_IRQ函数先保存了旧的栈帧结构指针,并在函数返回前恢复了旧的栈帧结构指针(目前还不是太理解在x86中的作用);
- 通过regs中的orig_ax取出中断向量号,这里会将负数再次转成正数;
- 执行irq_enter表明正式进入中断上下文,如将当前进程的preempt_count计数增加;exit_idle表明CPU将退出空闲状态,这里均不作展开;
- 通过percpu变量将中断向量转换成irq号,并根据irq号处理中断;
- 执行riq_exit表明退出中断上下文,并恢复旧的栈帖结构指针;
这里最让人困惑的是irq号,它和中断向量是什么关系?转化关系为什么又是percpu类型的?为了回答这些问题,我们的思路暂时切出中断发生后的过程,来了解一些中断管理类的概念和初始化动作。
smp系统出现之前,系统中不同的外部中断完全可以用中断向量来区分,但在smp系统中,CPU核数增加导致中断处理也变得复杂,每个CPU都可以处理不同的中断,如果还用全局性的中断向量来区分中断,所能表示的中断数目太少。那是否可以给每个CPU都设立独立的中断描述符表?不行,这样会大大增加内核实现的复杂性,它采用了一种变通的方式:所有外部中断通过irq号来区分,不同的中断(即不同的irq)可以使用相同的中断向量,只要这些中断被分配到不同的核上,例如在我的系统中查看中断信息得到如下结果:
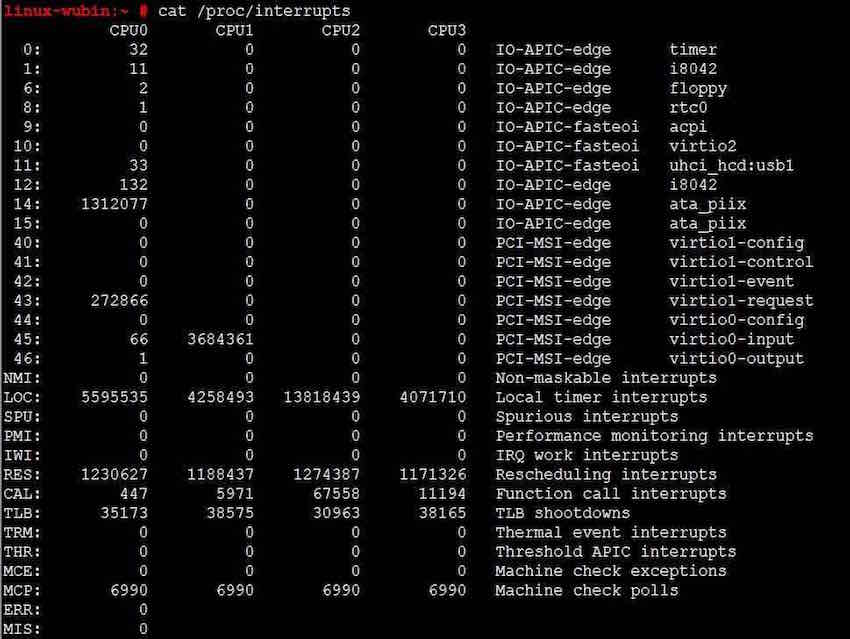
第一列中的数字即代表中断irq号,如0号irq代表ISA总线上的全局PIT时钟中断;通常来说0-15号irq对应传统ISA中断;16—39号开始分配给IOAPIC(i440fx中只有一个IOAPIC,占用24个irq);再往后的irq分配给MSI/MSI-X(i440fx中从16+24=40号开始)。上图中我们看不到系统给每个中断分配的中断向量,假设系统初始化时给irq 0分配了0号核的32号向量,给irq 1分配了1号核的32号向量,那么0号核的percpu数组vector_irq的32号元素就指向irq 0,而1号核的percpu数组vecotr_irq的32号元素指向irq 1,如此一来,虽然0号核和1号核收到的中断向量都是32,但是do_IRQ可以通过percpu的vector_irq找到不同的irq,并通handle_irq执行真正的中断处理逻辑。这就是percpu的vectro_irq的神奇作用,也回答了前篇所提出的为什么在驱动初始化前就可以给所有中断向量注册处理函数:中断描述符表中所指的函数只是一个伪入口(即桩函数),而非实际的处理函数;实际的处理函数是在驱动初始化时,在为设备申请了irq号之后,通过request_irq(irq, function…)注册给不同的irq的。
- 这里还可以再思考一个问题:系统中最多可处理的中断是多少个?是256么?
我们再切回中断的处理过程,在理解irq、中断向量、CPU核之间的关系后,可以看到handle_irq即是对每个中断进行实质性处理的核心函数,最终会调用request_irq函数注册的中断处理逻辑。下面我们就来分析一下handle_irq的实现逻辑。
4、中断处理逻辑handle_irq
该函数整体逻辑比较简单:先将irq转换成struct irq_desc结构,然后调用的generic_handle_irq_desc函数。
arch/x86/kernel/irq_64.c:
bool handle_irq(unsigned irq, struct pt_regs *regs)
{
struct irq_desc *desc;
...
desc = irq_to_desc(irq);
if (unlikely(!desc))
return false;
generic_handle_irq_desc(irq, desc);
return true;
}
irq_desc结构体将包含与中断相关的所有关键信息,内核中将所有中断的irq_desc结构组织成一棵树的结构:
include/linux/irqdesc.h:
/**
* struct irq_desc - interrupt descriptor
* @irq_data: per irq and chip data passed down to chip functions
* @kstat_irqs: irq stats per cpu
* @handle_irq: highlevel irq-events handler
* @preflow_handler: handler called before the flow handler (currently used by sparc)
* @action: the irq action chain
* @status: status information
* @core_internal_state__do_not_mess_with_it: core internal status information
* @depth: disable-depth, for nested irq_disable() calls
* @wake_depth: enable depth, for multiple irq_set_irq_wake() callers
* @irq_count: stats field to detect stalled irqs
* @last_unhandled: aging timer for unhandled count
* @irqs_unhandled: stats field for spurious unhandled interrupts
* @threads_handled: stats field for deferred spurious detection of threaded handlers
* @threads_handled_last: comparator field for deferred spurious detection of theraded handlers
* @lock: locking for SMP
* @affinity_hint: hint to user space for preferred irq affinity
* @affinity_notify: context for notification of affinity changes
* @pending_mask: pending rebalanced interrupts
* @threads_oneshot: bitfield to handle shared oneshot threads
* @threads_active: number of irqaction threads currently running
* @wait_for_threads: wait queue for sync_irq to wait for threaded handlers
* @dir: /proc/irq/ procfs entry
* @name: flow handler name for /proc/interrupts output
*/
struct irq_desc {
struct irq_data irq_data;
unsigned int __percpu *kstat_irqs;
irq_flow_handler_t handle_irq;
struct irqaction *action; /* IRQ action list */
unsigned int status_use_accessors;
unsigned int core_internal_state__do_not_mess_with_it;
unsigned int depth; /* nested irq disables */
unsigned int wake_depth; /* nested wake enables */
unsigned int irq_count; /* For detecting broken IRQs */
unsigned long last_unhandled; /* Aging timer for unhandled count */
unsigned int irqs_unhandled;
atomic_t threads_handled;
int threads_handled_last;
raw_spinlock_t lock;
struct cpumask *percpu_enabled;
#ifdef CONFIG_SMP
const struct cpumask *affinity_hint;
struct irq_affinity_notify *affinity_notify;
#ifdef CONFIG_GENERIC_PENDING_IRQ
cpumask_var_t pending_mask;
#endif
#endif
unsigned long threads_oneshot;
atomic_t threads_active;
wait_queue_head_t wait_for_threads;
#ifdef CONFIG_PROC_FS
struct proc_dir_entry *dir;
#endif
int parent_irq;
struct module *owner;
const char *name;
} ____cacheline_internodealigned_in_smp;
...
/*
* Architectures call this to let the generic IRQ layer
* handle an interrupt. If the descriptor is attached to an
* irqchip-style controller then we call the ->handle_irq() handler,
* and it calls __do_IRQ() if it's attached to an irqtype-style controller.
*/
static inline void generic_handle_irq_desc(unsigned int irq, struct irq_desc *desc)
{
desc->handle_irq(irq, desc);
}
对于上述代码片断,我不再多作解释,大家可以对照代码注释仔细理解。这里的generic_handle_irq_desc函数通过内联的方式会调用每个中断对应的handle_irq函数。可能很多同学会把这里的handle_irq理解成就是用户(驱动程序)通过request_irq注册的中断处理函数。其实不然,这里的handle_irq仍然是一段通用的中断处理逻辑,用来实现对不同中断模式的处理和中断流控功能。这些通用的处理函数主要有三类:handle_level_irq、handle_edge_irq、handle_fasteoi_irq。
kernel/irq/chip.c:
/**
* handle_level_irq - Level type irq handler
* @irq: the interrupt number
* @desc: the interrupt description structure for this irq
*
* Level type interrupts are active as long as the hardware line has
* the active level. This may require to mask the interrupt and unmask
* it after the associated handler has acknowledged the device, so the
* interrupt line is back to inactive.
*/
void
handle_level_irq(unsigned int irq, struct irq_desc *desc)
{
...
}
/**
* handle_fasteoi_irq - irq handler for transparent controllers
* @irq: the interrupt number
* @desc: the interrupt description structure for this irq
*
* Only a single callback will be issued to the chip: an ->eoi()
* call when the interrupt has been serviced. This enables support
* for modern forms of interrupt handlers, which handle the flow
* details in hardware, transparently.
*/
void
handle_fasteoi_irq(unsigned int irq, struct irq_desc *desc)
{
...
}
/**
* handle_edge_irq - edge type IRQ handler
* @irq: the interrupt number
* @desc: the interrupt description structure for this irq
*
* Interrupt occures on the falling and/or rising edge of a hardware
* signal. The occurrence is latched into the irq controller hardware
* and must be acked in order to be reenabled. After the ack another
* interrupt can happen on the same source even before the first one
* is handled by the associated event handler. If this happens it
* might be necessary to disable (mask) the interrupt depending on the
* controller hardware. This requires to reenable the interrupt inside
* of the loop which handles the interrupts which have arrived while
* the handler was running. If all pending interrupts are handled, the
* loop is left.
*/
void
handle_edge_irq(unsigned int irq, struct irq_desc *desc)
{
...
}
这三类函数主要是针对不同物理电气特性的中断和中断控制器(如IO-APIC、支持MSI的PCI设备等)做不同的处理。有兴趣的同学可以结合intel IO-APIC说明和PCI规范来仔细理解里面的实现过程。
最后,这几类函数都会调用handle_irq_event,它会调用irq_desc中action的handler,这个函数指针,才是用户通过request_irq注册的中断处理函数。到这一步,才真正调用到实际的中断处理逻辑。
kernel/irq/handler.c:
irqreturn_t
handle_irq_event_percpu(struct irq_desc *desc, struct irqaction *action)
{
irqreturn_t retval = IRQ_NONE;
unsigned int flags = 0, irq = desc->irq_data.irq;
do {
irqreturn_t res;
res = action->handler(irq, action->dev_id);
...
switch (res) {
case IRQ_WAKE_THREAD:
/*
* Catch drivers which return WAKE_THREAD but
* did not set up a thread function
*/
if (unlikely(!action->thread_fn)) {
warn_no_thread(irq, action);
break;
}
irq_wake_thread(desc, action);
/* Fall through to add to randomness */
case IRQ_HANDLED:
flags |= action->flags;
break;
default:
break;
}
retval |= res;
action = action->next;
} while (action);
add_interrupt_randomness(irq, flags);
if (!noirqdebug)
note_interrupt(irq, desc, retval);
return retval;
}
irqreturn_t handle_irq_event(struct irq_desc *desc)
{
struct irqaction *action = desc->action;
irqreturn_t ret;
desc->istate &= ~IRQS_PENDING;
irqd_set(&desc->irq_data, IRQD_IRQ_INPROGRESS);
raw_spin_unlock(&desc->lock);
ret = handle_irq_event_percpu(desc, action);
raw_spin_lock(&desc->lock);
irqd_clear(&desc->irq_data, IRQD_IRQ_INPROGRESS);
return ret;
}
5、中断返回ret_from_intr
当irq_desc的action处理完毕之后,中断处理过程将逐步返回到ret_from_intr:
arch/x86/kernel/entry_64.S:
ret_from_intr:
DISABLE_INTERRUPTS(CLBR_NONE)
TRACE_IRQS_OFF
decl PER_CPU_VAR(irq_count)
/* Restore saved previous stack */
popq %rsi
leaq ARGOFFSET-RBP(%rsi), %rsp
exit_intr:
GET_THREAD_INFO(%rcx)
testl $3,CS-ARGOFFSET(%rsp)
je retint_kernel
/* Interrupt came from user space */
/*
* Has a correct top of stack, but a partial stack frame
* %rcx: thread info. Interrupts off.
*/
retint_with_reschedule:
movl $_TIF_WORK_MASK,%edi
retint_check:
LOCKDEP_SYS_EXIT_IRQ
movl TI_flags(%rcx),%edx
andl %edi,%edx
jnz retint_careful
retint_swapgs: /* return to user-space */
/*
* The iretq could re-enable interrupts:
*/
DISABLE_INTERRUPTS(CLBR_ANY)
TRACE_IRQS_IRETQ
SWAPGS
jmp restore_args
retint_restore_args: /* return to kernel space */
DISABLE_INTERRUPTS(CLBR_ANY)
/*
* The iretq could re-enable interrupts:
*/
TRACE_IRQS_IRETQ
restore_args:
RESTORE_ARGS 1,8,1
irq_return:
INTERRUPT_RETURN
上述过程首先判断中断发生时是在用户态还是在内核态,
- 如果是在内核态,就跳转到retint_kernel执行,这里会根据内核是否打开抢占进行不同的处理:如果内核不可抢占,那就恢复寄存器后返回到被中断的上下文继续执行;如果是可抢占的,那就可以进行调度。
- 如果是在用户态,就进行调度及信号相关的判断和处理;处理完成并恢复寄存器后,便通过iretq指令返回被中断的上下文继续执行。
至此,CPU上中断处理的整个系统过程完美结束,这真是一个漫长的旅途:->
中断处理如何优化?-软中断
通过前文的分析,我们看到中断的处理过程已经比较复杂了,即便如此,系统工程师们仍努力在思考如何改进中断的处理。一个显著的问题就是,如果CPU每次都是等整个中断处理逻辑执行完毕之后再开始响应下一个中断,那后续中断处理的实时性就会受影响,而且长时间处于中断上下文也会影响时钟和任务调度。于是,内核工程师想了一个办法:把中断的处理分成两部分:一部分是立刻要做的(通常是和硬件相关的部分),并且只有等这部分做完了才能响应下一个中断,这部分通常处理时间很短,我们称这部分为上半部;另一部分是可以晚些时候处理(偏上层逻辑的部分),并且在处理这部分工作的时候是可以响应一下个中断的,这部分通常处理时间较长,我们称之为下半部。软中断就是下半部的一种实现方式,它大大提升了中断处理的实时性。
转载请注明:吴斌的博客 » 【计算子系统】CPU中断处理